
The deployment of a machine learning (ML) model to production starts with actually building the model, which can be done in several ways and with many tools.
The approach and tools used at the development stage are very important at ensuring the smooth integration of the basic units that make up the machine learning pipeline. If these are not put into consideration before starting a project, there’s a huge chance of you ending up with an ML system having low efficiency and high latency.
For instance, using a function that has been deprecated might still work, but it tends to raise warnings and, as such, increases the response time of the system.
The first thing to do in order to ensure this good integration of all system units is to have a system architecture (blueprint) that shows the end-to-end integration of each logical part in the system. Below is the designed system architecture for this mini-project.
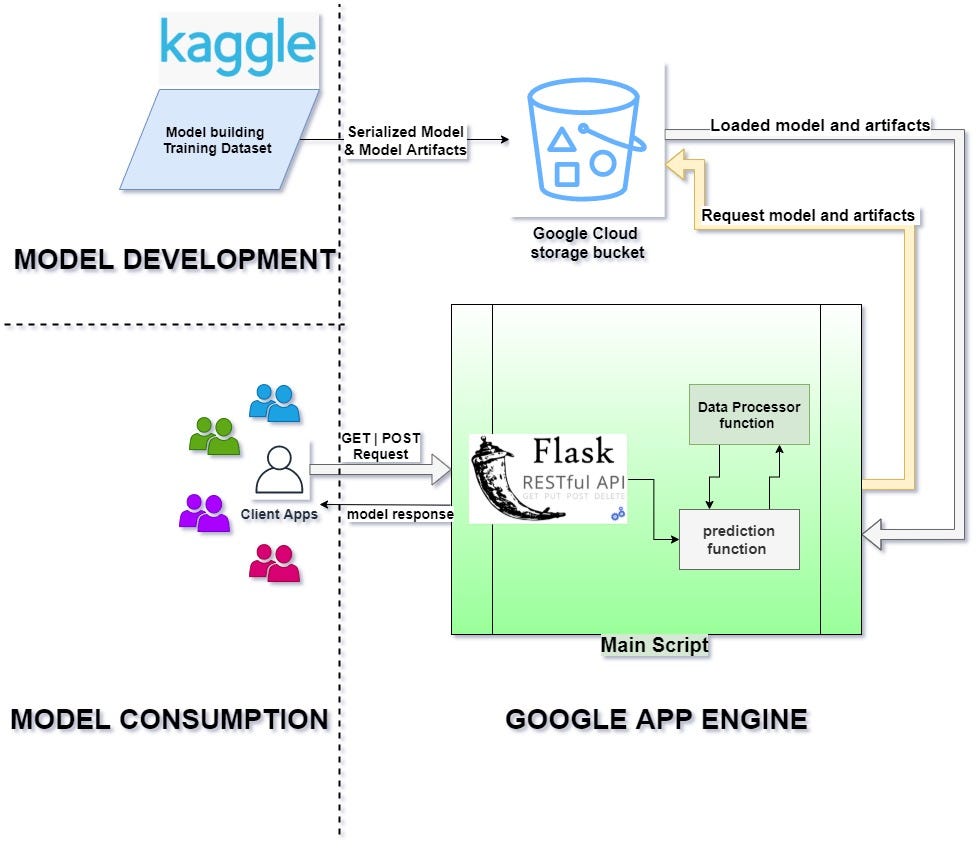
Model Development
When we discuss model development, we’re talking about an iterative process where hypotheses are tested and models are derived, trained, tested, and built until a model with desired results is achieved.
This is the fun part for data scientist teams, where they can use their machine learning skills for tasks such as exploratory data analysis, feature engineering, model training, and evaluations on the given data.
The model used in this project was built and serialized on this Kaggle kernel using the titanic dataset. Note that I only used existing modules in standard packages such as Pandas, NumPy and sklearn so as not to end up building custom modules. you can take a look at my previous post [1]“Deployment of Machine learning Model Demystified (Part 2)” to know more about a custom pipeline
The performance of the model can be greatly improved on with feature transformation, but most transformers that work best on the data are not available on sklearn…
Comments 0 Responses