
Introduction
Every data science task needs data. Specifically, data that’s clean and understandable by the system it’s being fed into. When it comes to images, a computer needs to see what human eyes see.
For example, humans have the ability to identify and classify objects. Similarly, we can use computer vision to interpret visual data that it receives. That’s where image annotation comes into the picture.
Image annotation has a critical role in computer vision. The goal of image annotation is to assign relevant, task-specific labels to images. This could include text-based labels (classes), labels that are drawn on images (i.e. bounding boxes), or even pixel-level labels. We’ll explore this range of different annotation techniques below.
Artificial intelligence requires more human intervention than we actually think. To prepare highly-accurate training data, we have to annotate images to get the right results. Data annotation often requires a high level of domain knowledge, which only experts from that particular field can provide.
Computer Vision tasks where annotation comes into play:
- Object Detection
- Line/Boundary Detection
- Segmentation
- Pose Estimation / Landmark Recognition
- Image Classification
1) Object Detection
There are two main techniques to perform object detection namely 2D and 3D Bounding Boxes.
The polygon method is also used for objects with irregular shapes. Let’s discuss them in detail.
2D Bounding Boxes
In this method, the annotator simply has to draw rectangular boxes around objects to be detected. They are used to define the location of the object in the image. The bounding box can be determined by the x and y-axis coordinates in the upper-left corner and the x and y-axis coordinates in the lower-right corner of the rectangle.

Pros and Cons:
- Very quick and easy to label.
- Fails to provide crucial information such as the orientation of objects, which is vital for many applications.
- Includes the background pixels which are not a part of the object. This may affect training.
3D Bounding Boxes or Cuboid
Similar to the 2D bounding box, except they can also show the depth of the target object under question. This kind of annotation is done by back-projecting the bounding box on the 2D image plane to the 3D cuboid. It allows systems to distinguish features like volume and position in a 3D space.

Pros and Cons
- Solves the problem of object orientation.
- When the object is blocked, the annotator has to assume the dimensions of the box, which may also affect the training.
- It also includes the background pixels that may affect the training.
Polygons
Sometimes, annotators have to label objects that are irregular in shape. In such cases, polygons are used. The annotator simply has to mark the edges of the object, and we’ll get a perfect outline of the object to be detected.

Pros and Cons:
- The main advantage of polygon labeling is that it eliminates background pixels and captures the exact dimensions of the object.
- Very time-consuming and difficult to annotate if the shape of the object is complex.
2) Line/Boundary Detection (Lines and Splines)
To demarcate boundaries, lines and splines are useful. The pixels that divide one region from another region are annotated.

Pros and Cons:
- The advantage of this method is that the pixels lying on one line need not all be contiguous. This can be very useful when trying to detect lines with short breaks in them due to noise, or when objects are partially occluded.
- Manually annotating lines in an image can be very tiring and time-consuming, especially if there are many lines in the image.
- Can give misleading results when objects happen to be aligned.
3) Pose Estimation / Landmark Recognition
In many computer vision applications, the neural network often needs to recognize essential points of interest in the input image. We refer to these points as landmarks or key points. In such applications, we want the neural network to output the coordinates (x, y) of landmark points.

4) Segmentation
Image segmentation is the process of partitioning an image into multiple segments. Image segmentation is typically used to locate objects and boundaries in images at a pixel-level.
There are different kinds of image segmentation.
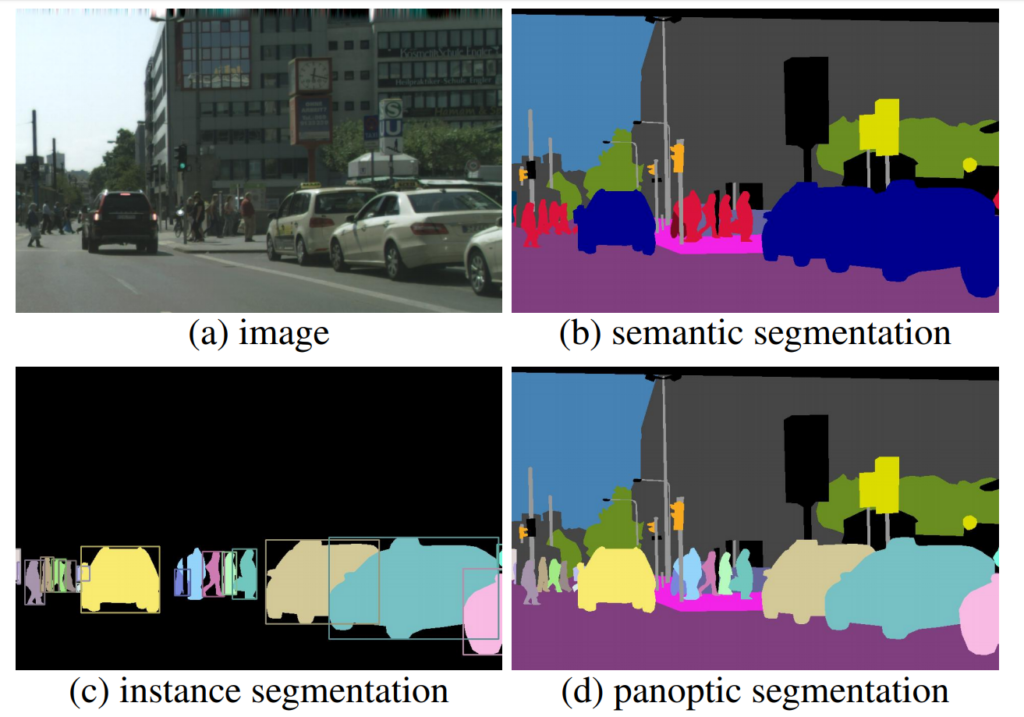
- Semantic Segmentation: Semantic segmentation is a machine learning task that requires a pixel-wise annotation, where every pixel in the image is assigned to a class. Each pixel carries semantic meaning. This is primarily used in cases where environmental context is very important.
- Instance Segmentation: Instance segmentation is a subtype of image segmentation that identifies each instance of each object within the image at the pixel level. Instance segmentation, along with semantic segmentation, is one of two granularity levels of image segmentation.
- Panoptic Segmentation: The panoptic segmentation combines semantic and instance segmentation such that all pixels are assigned a class label and all object instances are uniquely segmented.
5) Image Classification
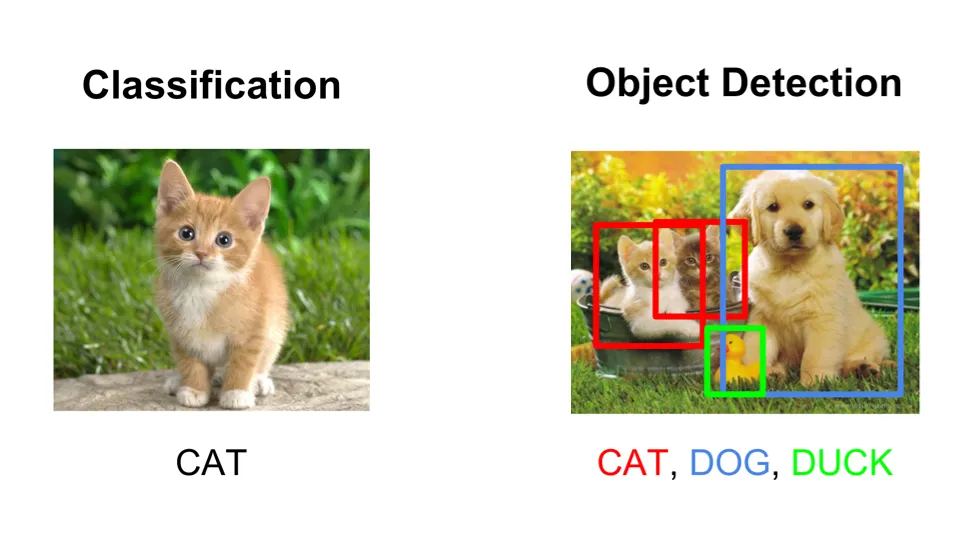
Image classification is different from object detection. While object detection aims to both identify and locate objects, image classification aims to recognize/identify specific object classes. A common example of this use case is classifying pictures of cats and dogs. The annotator has to assign an image of a dog the class label “dog”—and the same for images of cats (class label “cat”).
Use Cases for Image Annotation
In this section, we’ll be discussing how image annotation can be used to help ML models perform industry-specific tasks:
- Retail: 2D bounding boxes can be used to annotate images of products that can then be used by machine learning algorithms to predict costs and other attributes. Image classification also helps in this.
- Medicine: Polygons can be used to label organs in medical X-rays so that they can be fed into deep learning models to train for deformities or defects in the X-ray. This is one of the most critical applications of image annotation, and it requires high domain knowledge of medical experts.
- Self-Driving Cars: This is yet another important field where image annotation can be applied. Semantic segmentation can be used to label each pixel of images so that the vehicle can be aware and can sense obstacles in its way. The research in this field is still ongoing.
- Emotion Detection: Landmark points can be used to detect the emotions of a person (happy, sad, or neutral). This finds application in situations when gauging a subject’s emotional reaction to a given piece of content.
- Manufacturing Industries: Lines and splines can be used to annotate images of factories for lines following robots to work. This can help automate the process of manufacturing, and human labor can be minimized.
Common Challenges with Image Annotation
- Time Complexity: A lot of time is consumed by annotators to manually annotate images. Machine learning requires huge datasets, and a lot of time is needed to effectively label these image-based datasets.
- Computational Complexity: Machine learning requires accurately-labeled data to run the model. If the annotator injects any kind of error while labeling images, it may affect the training and all the hard work may go in vain.
- Domain Knowledge: As mentioned earlier, image annotation often requires high domain knowledge in a given field. So we need annotators who know what to label, as well as those who are experts in that field.
Conclusion
In this article, we introduced and discussed various techniques for image annotation, a crucial step in preparing data for machine learning:
- Object Detection
- Line/Boundary Detection
- Segmentation
- Pose Estimation / Landmark Recognition
- Image Classification
All these above techniques have their own pros and cons, and the applications where you’ll need to use them. After reading this, you should have a firm understanding of what you want your final computer vision model to do while planning your data annotation process.
Comments 0 Responses