
Isn’t it magic to annotate objects in AR?
I was inspired by this example of Core ML + ARKit. But I found one significant disadvantage — it doesn’t place annotations on objects automatically. Instead, you need to center the object in your camera view and use your finger to place an annotation.
In my opinion, this destroys user expectations, so I decided to fix that and build a more immersive user experience using object detection in augmented reality.
Get started
- Download the source code.
- Open the project and navigate to Signing & Capabilities.
- Select your Apple Developer account, add the bundle identifier, and create a provisioning profile (I recommend using Automatically manage signing).
- Connect your device.
- Build and run.
- Enjoy!
Now let’s see what happens under the hood
Out app has two main entities. The first one is the object detection service (shown below): it takes an image as input and returns a bounding box and class label of the recognized object. The second is the ViewController, the place where all the AR magic happens:
class ObjectDetectionService {
//1
var mlModel = try! VNCoreMLModel(for: YOLOv3Int8LUT(configuration: MLModelConfiguration()).model)
//2
lazy var coreMLRequest: VNCoreMLRequest = {
return VNCoreMLRequest(model: mlModel,
completionHandler: self.coreMlRequestHandler)
}()
//...
//3
func detect(on request: Request, completion: @escaping (Result) -> Void) {
self.completion = completion
let orientation = CGImagePropertyOrientation(rawValue: UIDevice.current.exifOrientation) ?? .up
let imageRequestHandler = VNImageRequestHandler(cvPixelBuffer: request.pixelBuffer,
orientation: orientation)
do {
try imageRequestHandler.perform([coreMLRequest])
} catch {
complete(.failure(error))
}
}
} Below are the steps as identified in the inline comments in the code block above
- Initialize the Core ML model: In this case, we’re working with a Swifty representation of a pre-trained machine learning model. Apple provides dozens of open-source models here. Also, you can create your own by using tools like Create ML.
- Initialize an image analysis request, which uses the Core ML model to process input images.
- detect method that instantiates the handler to perform Vision requests on a single image. It uses a Core Video pixel buffer because it can be easily taken from the current ARFrame, since pixel buffer doesn’t store information about the current image orientation. We take the current device orientation and map it into an Exif orientation format.
Handling detection results
As you may have noticed, in step 2 we provided a coreMlRequestHandler. This handler is called once object detection has been performed (i.e. as a result of the detect method:
func coreMlRequestHandler(_ request: VNRequest?, error: Error?) {
//1
if let error = error {
complete(.failure(error))
return
}
//2
guard let request = request, let results = request.results as? [VNRecognizedObjectObservation] else {
complete(.failure(RecognitionError.resultIsEmpty))
return
}
//3
guard let result = results.first(where: { $0.confidence > 0.8 }),
let classification = result.labels.first else {
complete(.failure(RecognitionError.lowConfidence))
return
}
//4
let response = Response(boundingBox: result.boundingBox,
classification: classification.identifier)
complete(.success(response))
}
//5
func complete(_ result: Result) {
DispatchQueue.main.async {
self.completion?(result)
self.completion = nil
}
} As previously, the following steps align with the inline comments:
- Here, we just check to see if the detection finished with an error.
- Map detection results to VNRecognizedObjectObservation, which stores all necessary information about the recognized objects.
- In this step, we filter the array of results and find the first one where the confidence of the detection is greater than 80% (in order to get reduce false positives) and take the first label that classifies the recognized object.
- This is the last thing to do in recognition — just send the result to completion.
- The process of object detection was run on the global queue—we need to push the stream of execution back to the main queue to safely cope with UI-related tasks.
Adding augmented reality
Our ViewController is responsible for looping calls of the object detection service and placing annotations whenever an object is recognized. Moreover, the controller increases the accuracy with which annotations are of placed—it doesn’t allow you to place an annotation if the device is moving, the object is too far from the camera, etc.
The ViewController seems a bit overloaded—I would recommend splitting responsibilities into different classes.
Looping object detection
To make automatic annotation, we need to persistently loop the process of getting a snapshot of the current frame and sending it to the detection service.
func loopObjectDetection() {
throttler.throttle { [weak self] in
if self?.isDetectionEnabled == true {
self?.performDetection()
}
self?.loopObjectDetection()
}
}In this code example, you can see the recursion with slight improvements. It uses throttling to do this.
As you might have noticed, performDetection runs only when isDetectionEnabled is set to true—this property brings the most performance and accuracy improvements.
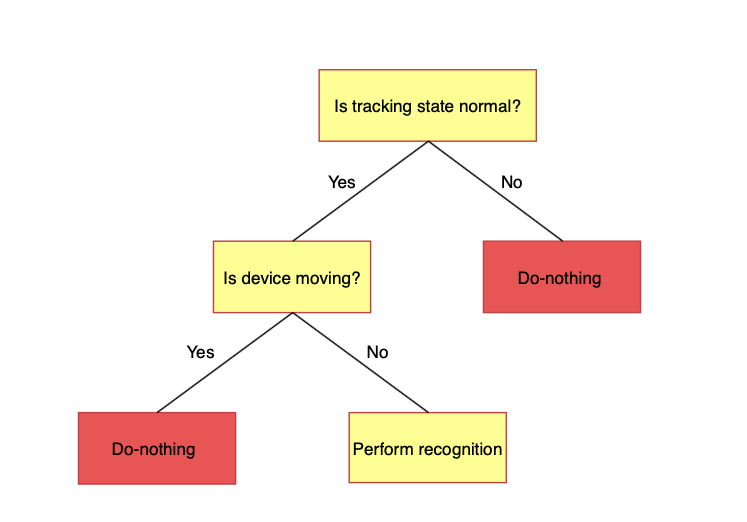
By conforming to the ARSessionDelegate protocol, the controller can track all changes in the current AR session. There are many cases where, in a particular state, we don’t need to run object detection, so we set isDetectionEnabled to false(e.g when AR tracking is limited, initializing is happening, or there is no surface detected). This view controller implements all methods from ARSessionDelegate, and these methods calls onSessionUpdate, which determines the session state and considers whether detection should continue.
Device movement
Take a closer look at the speed limiter. When the device is moving too fast, it adversely affects annotation accuracy. In func session(_ session: ARSession, didUpdate frame: ARFrame) we implement logic that tracks device motion and sets isDetectionEnabled to false whenever the user drives over the speed limit.
func session(_ session: ARSession, didUpdate frame: ARFrame) {
let transform = SCNMatrix4(frame.camera.transform)
let orientation = SCNVector3(-transform.m31, -transform.m32, transform.m33)
let location = SCNVector3(transform.m41, transform.m42, transform.m43)
let currentPositionOfCamera = orientation + location
if let lastLocation = lastLocation {
let speed = (lastLocation - currentPositionOfCamera).length()
isDetectionEnabled = speed < 0.0025
}
lastLocation = currentPositionOfCamera
}Here, we just take the camera node’s position relative to the scene’s world coordinate space and compare it with the previous location, and if the speed over 0.0025 coordinates per frame, detection will be terminated by setting isDetectionEnabled to false.
Object detection
When all complex requirements of accuracy and performance are satisfied, finally, it’s time to turn to our object detection model.
func performDetection() {
//1
guard let pixelBuffer = sceneView.session.currentFrame?.capturedImage else { return }
objectDetectionService.detect(on: .init(pixelBuffer: pixelBuffer)) { [weak self] result in
guard let self = self else { return }
switch result {
case .success(let response):
//2
let rectOfInterest = VNImageRectForNormalizedRect(
response.boundingBox,
Int(self.sceneView.bounds.width),
Int(self.sceneView.bounds.height))
//3
self.addAnnotation(rectOfInterest: rectOfInterest,
text: response.classification)
case .failure(let error): break
}
}
}- Here, we take a snapshot of the current ARFrame and send it to the object detection service. Then we just wait for the callback.
- When the callback is called with success, we need to convert the normalized rect of the recognized object to sceneView size. Thankfully, all the complicated math is done by the VNImageRectForNormalizedRect function.
- And the last thing we do is to place an annotation on the scene root node.
Adding annotations
Let’s have a look at the addAnnotation method. It places an annotation if possible—take a closer look at following code to see how this is implemented.
func addAnnotation(rectOfInterest rect: CGRect, text: String) {
//1
let point = CGPoint(x: rect.midX, y: rect.midY)
let scnHitTestResults = sceneView.hitTest(point,
options: [SCNHitTestOption.searchMode: SCNHitTestSearchMode.all.rawValue])
guard !scnHitTestResults.contains(where: { $0.node.name == BubbleNode.name }) else { return }
//2
guard let raycastQuery = sceneView.raycastQuery(from: point,
allowing: .existingPlaneInfinite,
alignment: .horizontal),
let raycastResult = sceneView.session.raycast(raycastQuery).first else { return }
let position = SCNVector3(raycastResult.worldTransform.columns.3.x,
raycastResult.worldTransform.columns.3.y,
raycastResult.worldTransform.columns.3.z)
//3
guard let cameraPosition = sceneView.pointOfView?.position else { return }
let distance = (position - cameraPosition).length()
guard distance <= 0.5 else { return }
//4
let bubbleNode = BubbleNode(text: text)
bubbleNode.worldPosition = position
sceneView.prepare([bubbleNode]) { [weak self] _ in
self?.sceneView.scene.rootNode.addChildNode(bubbleNode)
}
}1. In the first step, we exclude the situation when for one detected object, more than one annotation is placed. Instantiate a center point of the recognized object on the screen using sceneView’s coordinate system. The hitTest method searches the renderer’s scene for objects corresponding to a point, and it uses SCNHitTestSearchMode.all in order to find all intersections of the sent ray with nodes. If in the received result it finds a BubbleNode (the actual name of your annotation filtered by node name), the method’s execution ends.
2. The next step is to find a plane and point in the world system coordinates where the bubble should be placed. This is done by using raycasting methods raycastQuery and raycast(raycastQuery).
3. Here, we implement restricting code that doesn’t allow you to place the bubble if it’s too far from the user’s camera—in this example, the maximum distance between an object and the device is 0,5 m. Feel free to tune this value for your particular needs.
4. And finally, last but not least, we place the annotation on the rootNode of the scene. Set the worldPosition of the newly-created BubbleNode to the position determined in step 2, and place and add a child node to the rootNode.
Conclusion
I’m sure in the future we’ll see more applications that use CoreML and ARKit together, as they complement themselves perfectly. I believe that the new evolution branch of UX starts here. See you later!
If you enjoyed this post, please leave some claps. 👏👏👏
Comments 0 Responses