
Machine learning systems built for production are required to efficiently train, deploy, and update your machine learning models. Various factors have to be considered while deciding on the architecture of each system. Parts of this blog post are based on the Coursera and GCP (Google Cloud Platform) course on building production machine learning systems. Below, I’ll list some of the concerns in building a scalable machine learning system:
- Scaling the model training and serving process.
- Keeping track of multiple experiments with different hyper-parameters.
- Reproducing the results and retraining models in a predictive manner.
- Keeping track of different models and their model performance over time (i.e model drift).
- Dynamically retraining models with new data and rollback models.
Companies like Uber (Michaelangelo), Google, Airbnb (Bighead), and Facebook (FBlearner Flow) all have platforms that solve the above problems. But not all of us have the kinds of resources that these big players have. That said, let’s take a look at how we might be able to build our own production ML system.
Components of a Machine Learning (ML) System
For different areas of ML like computer vision, NLP (natural language processing), and recommendation systems, there are a lot of articles about the new models being developed like BERT, YOLO, SSD, etc. However, in most cases, building a model accounts for only 5–10% of the work in a production ML system!
There are quite a few other components to consider — data ingestion, data pre-processing, model training, model serving, and model monitoring.
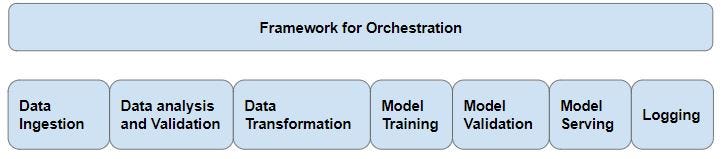
Data Ingestion and Processing
For most applications, data can be classified into three types:
- Unstructured data stored in a system like Amazon S3 or Google Cloud storage.
- Structured data stored in a relational database like MySQL or distributed relational database services like Amazon RDS, Google Big Query, etc.
- Streaming data coming from a web application or IoT device.
The first step in the ML pipeline is to ingest the correct data from the relevant data source and then clean or modify it for your application. Below are some of the tools used to ingest and manipulate data:
DataflowRunner— A runner for Apache Beam on Google Cloud. Apache Beam can be used for batch and stream processing, hence the same pipeline can be used for processing batch data (during training) and for streaming data during prediction.
Apache Airflow — The managed version of Airflow is GCP’s Cloud Composer and is used for workflow orchestration. Airflow can be used to author, schedule and monitor workflows.
Streaming Data — There are various tools available for ingesting and processing stream data like Apache Kafka, Spark Streaming, and Cloud Pub/Sub.
Argo — Argo is an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. Argo can be used to specify, schedule, and coordinate the running of complex workflows and applications on Kubernetes.
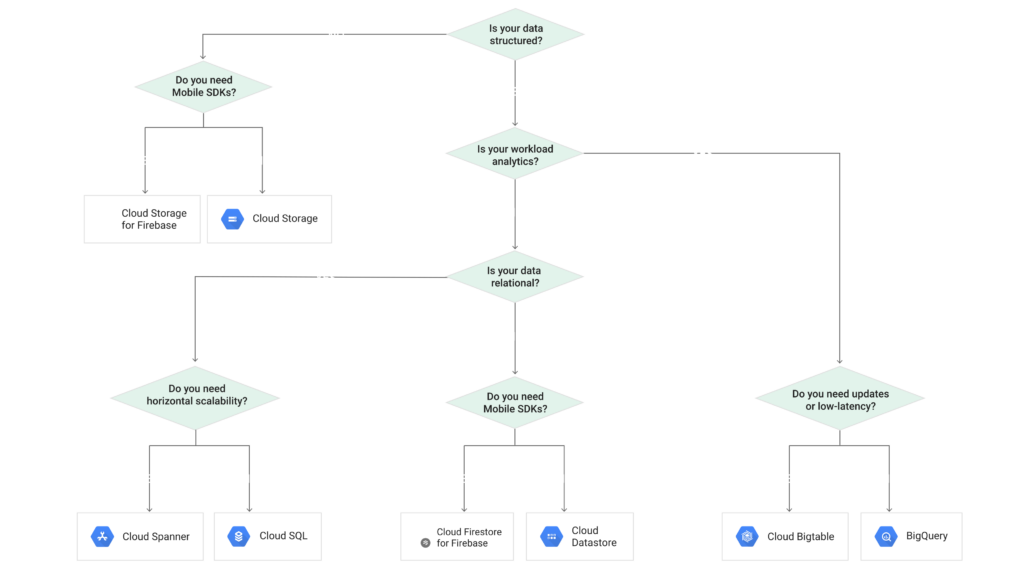
Below picture shows how to choose the right storage option on Google cloud
Data Validation
Data validation is needed to mitigate training-serving skew. The inputs have to be checked to determine if they’re of the correct type, and input distributions have to be continuously monitored because if the input distribution has significantly changed, then the model performance will degrade, which will require retraining. It can also point to a change in the input source type or some kind of client side error.
IO and Compute — Depending on the use case, the training time can be IO (Input/Output) bound, compute bound, or both! Compute bound means that more CPU/GPU/TPU resources are needed to reduce the training time. This can be done relatively easily by adding more workers.
IO bound means that it’s taking more time to read the data and transfer them to the compute resource (CPU/GPU/TPU), which is idle for a long time during data loading. Below are three methods for reading files—from slowest to fastest—to solve the IO speed issues:
- Reading using Pandas or Python commands — This is the slowest method and should be used when working with small datasets and during prototyping and debugging.
- Using TensorFlow native methods — These function are implemented in C++, hence they’re faster than the above method.
- TFRecord — This is the fastest method. TFRecord format is a simple format for storing a sequence of binary records.
raw_dataset = tf.data.TFRecordDataset(filenames)
Model Training
For model training, one can use fully-managed services like AWS Sagemaker or Cloud ML Engine. With both of these services, users don’t have to worry about provision instances to scale the training process, and they also support managed model serving. To create your own distributed training system, see below —
Distributed Training — TensorFlow supports multiple distributed training strategies. They can be classified under two groups:
Data parallelism — In data parallelism, the data is divided into smaller groups and training is done on different workers/machines, and then the parameters are updated every run. Below are some techniques to update the parameters
- Parameter Server strategy (Async) — In this approach, specific workers act as parameter servers. This is the most commonly used technique and is the most stable. As this is an async approach, sometimes different worker’s parameters can be out of sync, which can increase the convergence time.
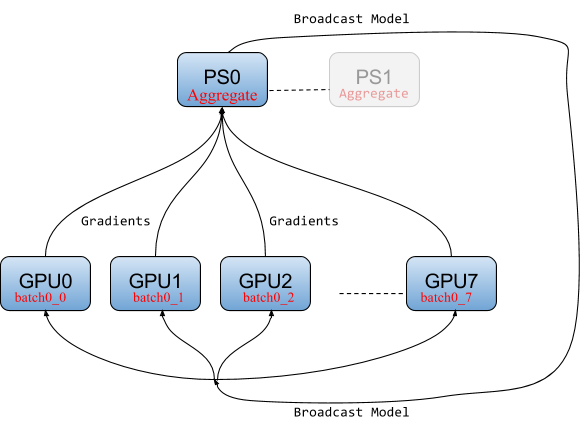
- All Reduce (mirrored strategy) — This is a relatively new approach where each worker holds a replica of the parameters, and after every pass all the workers are synced. This approach works well when there is a high speed link between the workers. As such, it works well for TPUs and workers with multiple GPUs.
There are a few other strategies: The Multi-worker Mirrored strategy and the TPU strategy. To learn more about distributed training using TensorFlow, check out the post on O’Reilly:
Horovod — Horovod is an open source distributed training framework released by Uber that makes distributed training easier, and it supports TensorFlow, Keras, PyTorch, and Apache MXNet.
Model parallelism — Model parallelism is different from data parallelism, as here we distribute the model graph over different workers. This is needed for very large models. Mesh TensorFlow and GPipe are some of the libraries that can be used for model parallelism.
Model predictions — Static vs Dynamic serving
There are three ways in which model predictions can be done —
- Batch Predictions or Offline — In this case, predictions are done offline on a large sets of inputs, and the prediction results are stored with the input to be used later. This works for applications where inputs are known in advance, for example predicting house prices, generating recommendations offline, etc. A prediction API can also be used; however, it’s cheaper, faster, and simpler to just load the model and do predictions.
- Online Predictions — In this case, the inputs are not known in advance, and predictions have to be made based on inputs supplied by the user. For these applications, it’s better to create a scalable perdition API using TensorFlow serving, Cloud ML Engine, or Cloud AutoML. In some applications, prediction latency is very important, like credit card fraud predictions, etc.
- Edge Predictions — In this case, predictions have to be done on the edge device, such as a mobile phone, Raspberry Pi, or the Coral Edge TPU. In these applications, models size has to be compressed to fit on these devices and model latency also has to be reduced. There are three ways to reduce the model size:
a) Graph freezing — Freezing the graph converts variable nodes to constant nodes, which can then be stored with the graph, which reduces model size.
b) Graph transform tool — The graph transform tool removes nodes that aren’t used during prediction and helps reduce model size (eg the batch norm layer can be removed during inference).
c) Weight quantization — This method results in the biggest size decrease. Typically, weights are stored as 32-bit floating point numbers; however, by converting them to 8-bit integers, the model size can be significantly reduced. However, this can results in decreases in accuracy, which differs from application to application. To prevent the loss of accuracy, quantization aware training and quantization parameter tuning can be used.
Open Source Platforms for ML systems
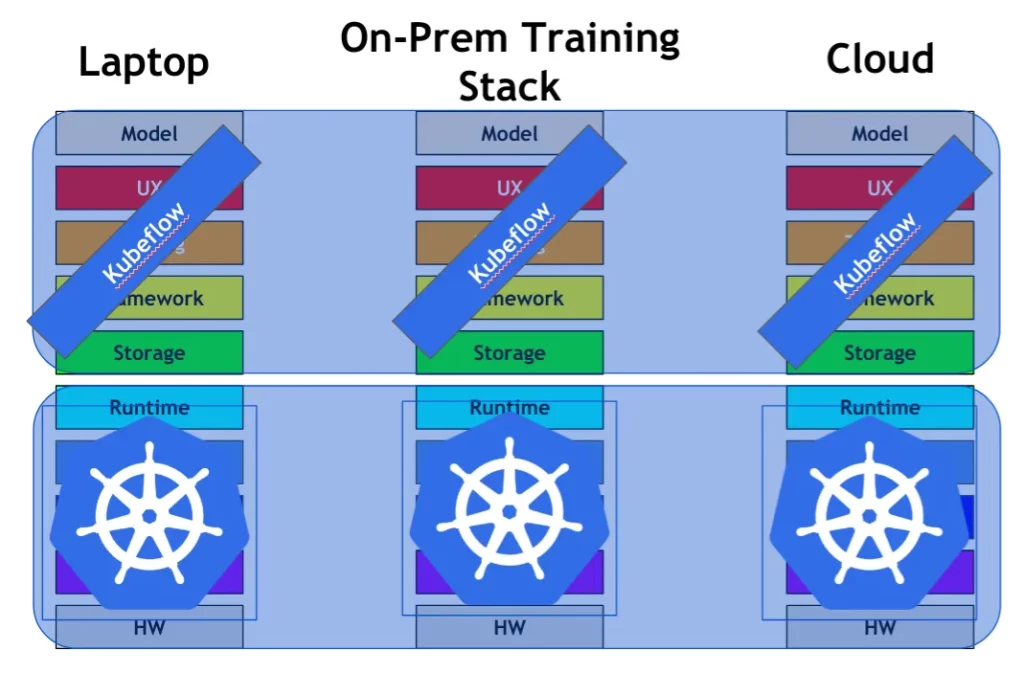
Kubeflow — Kubeflow is a open source platform built on top on Kubernetes that allows scalable training and serving of machine learning models. Kubeflow uses Seldon Core for deploying machine learning models on a Kubernetes cluster. Kubeflow can run on any cloud infrastructure, and one of the key advantages of using Kubeflow is that the system can then be deployed on an on-premise infrastructure.
MLFlow — MLFlow is an open source platform for managing the machine learning lifecycle. It has three main components, as shown below:

Polyaxon — Polyaxon is another open source platform for managing the lifecycle of machine learning applications. Polyaxon also runs on top of Kubernetes.
TensorFlow Extended (TFX) — TFX is an end-to-end platform for deploying production ML pipelines. TensorFlow serving together with Kubernetes can be used to create a scalable model serving system. TFX also has other components like TFX transform and TFX data validation. TFX uses Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. TFX uses Apache Beam for running batch and streaming data processing tasks.
MLFlow can be used on top of Kubeflow to solve most of the problems listed at start of the blog. The advantage of Kubeflow, as compared to TFX, is that since Kubeflow is built on top of Kubernetes, you don’t have to worry about scaling, etc.
Conclusion
These are only some of the things you have to worry about when building a production ML system. Various other issues include logging and monitoring the state of various services. There are numerous other tools like Istio, which can be used to secure and monitor your system. The Cloud native computing foundation builds and supports various other projects for cloud native scalable systems.
Lot of these tools are still under active development, and as such, building scalable machine learning systems remains a very challenging problem. I’m passionate about building production machine learning systems to solve challenging real-world problems. I’m actively looking for ML/AI engineer positions, and you can contact me here.
Comments 0 Responses