
Introduction
Speaking to your home is no longer a sci-fi fantasy but a common part of everyday life for many. This is undoubtedly exciting, but the accessibility of voice assistants (Amazon Alexa, Google Assistant, etc…) is now more crucial than ever. In fact, assisting someone with a disability has a bigger positive impact than helping someone set a timer while baking.
With the aim to provide this kind of conversational assistance to those with visual impairments, a team of students have been working with the Interaction Lab at Heriot-Watt University. This two part series will explore their work.
Team
This project was planned, designed, and built over a 12 week period as part of a course called “Conversational Agents and Spoken Language Processing”. If this is a class or an area that interests you, take a look at the MSc in Conversational AI at Heriot-Watt.
Students:
Amit Parekh (LinkedIn, GitHub)
Vincent Larcher
Lucas Dumy
Alexandre Cardaillac
Katerina Alexander
Hamish MacKinnon (GitHub)
Théo Ferreira
Supervisors:
Angus Addlesee (Medium, Twitter, LinkedIn)
Shubham Agarwal (Medium, Twitter, LinkedIn)
Verena Rieser (Twitter, LinkedIn)
Oliver Lemon (Twitter, LinkedIn)
What we Achieved: Developing AyeSaac
We initially planned to tailor our system (named AyeSaac) to be used in the living room. Once we started looking through real questions asked by blind people (VizWiz Dataset) however, it was plainly obvious that the kitchen was a more helpful room to choose. Your sofa doesn’t move often, but kitchen utensils on a counter do. Finding these utensils and reading text on food packaging were two noticeable tasks that we wanted to tackle.

Apps exist in this area. For example, Be My Eyes pairs its users with sighted volunteers through a video call. There are also automated apps that don’t involve any volunteers, such as TapTapSee that can identify objects in an image. Reading text aloud is also achievable using a device, called OrCam MyEye 2.0, that attaches to a user’s glasses.
These projects are fantastic but instead of using multiple apps and devices, we wanted AyeSaac to be a framework that incorporates these functions together. We decided to include the following in our initial version:
- Object Detection
- Reading Text (OCR)
- Color Detection
- Position Detection
In the following video, some of the team introduce AyeSaac and run through a demo at 4:35.
Getting More Technical
As detailed in the video (at 2:17), the architecture of AyeSaac looks like this:
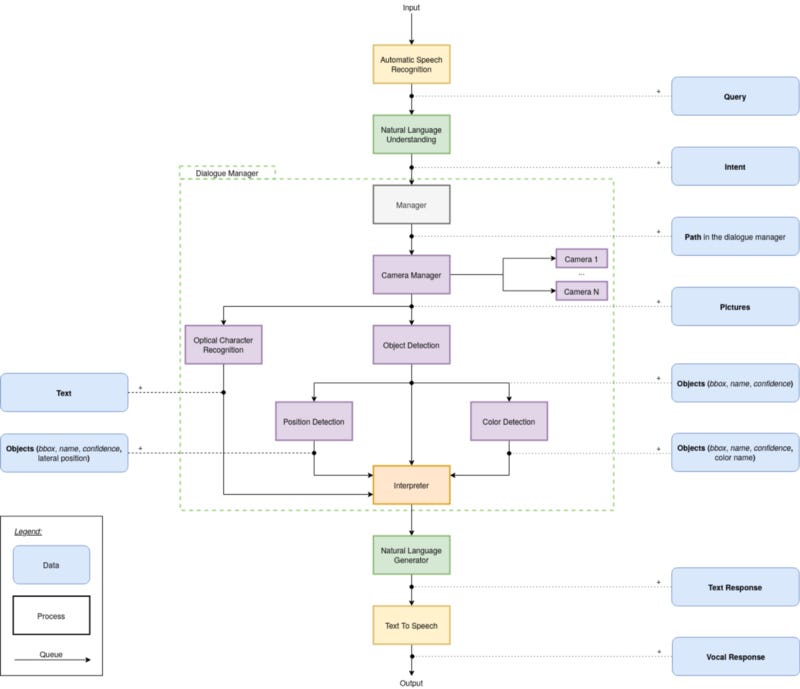
AyeSaac contains the following components:
- Speech Recognition (We used Watson) – converts the user’s voice to text.
- NLU (Rasa) – processes the text to understand what the user is asking the system. For example: detect color, read text, or find named object.
- Manager – decides on the path to take through the dialogue manager based upon Rasa’s output. For example: “What color is the bowl?” requires object detection and color detection, but not the position detection or OCR.
- Camera Manager – detects and extracts the visual input from a single or multiple cameras. Cameras can be in-built laptop cameras, external cameras (such as webcams or a Kinect), or mobile cameras if you want to run AyeSaac on a smartphone.
- OCR (Keras OCR) – extracts text from images. This is used if the user requires any text to be read.
- Object Detection (TensorFlow Object Detection) – identifies objects and locates them in the scene. This is used when users want to ask what is in front of them, whether a specific object is there, how many of them there are, etc…
- Position Detection – returns the horizontal positions of each object relative to the frame. With a Kinect attached, an object’s depth is also returned.
- Color Detection (SLIC segmentation algorithm & KNN clustering) – determines the most common color of each object in the scene and its name.
- Interpreter – receives the path chosen by the manager and the output of each relevant component. It combines this information to be consumed by the natural language generation (NLG).
- NLG (rule-based) – uses the information from the interpreter and the intent from the NLU to generate a textual answer to the question asked by the user.
- Text-to-Speech (Google TTS) – converts the textual answer to a spoken response for the user.
Next Steps:
As mentioned at the beginning of this article, we planned a deeper evaluation in collaboration with Royal Blind, which was unfortunately postponed due to coronavirus. Even though we couldn’t run a thorough evaluation, we’re aware of many ways that AyeSaac could be improved:
- Improving object detection. TensorFlow’s object detection model is trained using the Common Objects in Context (CoCo) dataset. This dataset is a great baseline, but it’s not tailored to the kitchen domain. For this reason, it would be beneficial to train a model on a more specific dataset (i.e. excluding airplanes and camels, but including spatulas and graters).
- Similarly, improving the NLU with a more tailored training corpus.
- Evaluating alternative OCR solutions for our use case. We chose to implement Keras OCR, but we didn’t have time to check whether Tesseract, for example, performed better for this use case.
- Utilizing depth detection. We lost access to our Kinect mid-way through this project because of coronavirus. Unfortunately, this meant that we couldn’t implement our improved object location using depth. Implementing this would allow the system to tell the user whether an object is in front of or behind the user.
- Understanding synonyms. Currently the system will detect a bowl, but it will also return a negative response when the user asks whether there is a “dish” around. This is obviously an issue that needs to be resolved to greatly improve usability and decrease potential user frustration.
- Adding functionality. Currently, AyeSaac can not answer all questions that could be asked (obviously there will always be out of scope questions). A question such as, “Is the toaster on?” could maybe be answered using current components, but the system would benefit from additional info. For example, a model to detect whether a toaster lever is up or down could be implemented. Alternatively, in a smart-home, AyeSaac could communicate with available IoT devices.
Comments 0 Responses