
In recent years, there’s been a steep increase in the number of write-ups and articles on ‘Artificial Intelligence’ (AI), ‘Machine Learning’ (ML) and ‘Big Data’—obviously because practical applications of these new technologies is trending upward in all business domains and in day-to-day life.
Oftentimes, online conversations centered on these technologies tend to interchange these terms, which is understandable given a lack of technical expertise. But somewhat surprisingly, quite a few tech-savvy authors and articles I’ve come across are also swapping these terminologies with each-other, despite the fact that AI, ML and big data are quite distinct from each other.
Whether you’re a non-technical member of an organization trying to decide what kind of data-based solution your team should invest in, a student just starting out in these fields, or anywhere in between—the aim of this article is to, once and for all, clear up the confusion.
Artificial Intelligence
Intelligence is basically defined as the ability to apply logic and reason to analyze inputs and, ultimately, make decisions. The same thing done by a machine or a non-living artificial being is termed as Artificial Intelligence. Just like a human, AI can take audio-visual inputs and process them to output desired results.
As stated on Technopedia:
Artificial intelligence is defined as the area of computer science that emphasizes the creation of intelligent machines that work and react like humans.
AI is very common these days and is used on almost all major Internet platforms in some way, and in fact, it’s very likely that you came here to this blog post after getting a suggestion by an AI.
While this is just the start of the AI age, it’s being used everywhere, from simple games like Pac-Man to fully-autonomous cars. We all have AI assistants on our phones like the Google Assistant, Apple’s Siri, Samsung’s Bixby, Amazon’s Alexa, and many more. The applications of AI are beyond imagination.
This article by BeeBom describes 10 applications of AI in our daily lives.
Humans have started to rely on machines for difficult tasks and complicated projects that require certain levels of precision. AI is still in its initial stages of development and therefore requires some human interaction. Even at such a stage, it’s capable of performing many tasks more efficiently and better than humans ever could.
Machine Learning
For a machine to be intelligent it has to learn how to process data, and there has to be a way to do so….you guessed it right — it’s machine “learning.”
Machine learning (ML) is the method of making computers learn and think as humans do. In fact, it’s similar to how babies learn — by observation.
The reason why machine learning is becoming so popular is because for it to work you don’t have to know how to solve a particular problem. All you need to know is the nature of a problem and its ideal answer, and then ML works like magic to solve the problem for you based on how many similar problems with correct answers you provide it with.
The learning is usually stored as a software artifact called a machine learning model. These models are trained on large amounts of data along with labels stating what the data represents.
For example: If you’re training an ML model to identify numbers using a camera, then the training data consists of images of the number along with a label stating which number is present in each given image.
Machine learning involves running algorithms over this data. These algorithms recognize patterns and trends in it and learn to predict the labels of new data.
In this way, ML models are able to make predictions about unseen data based on what they’ve learned from the data they were trained on.
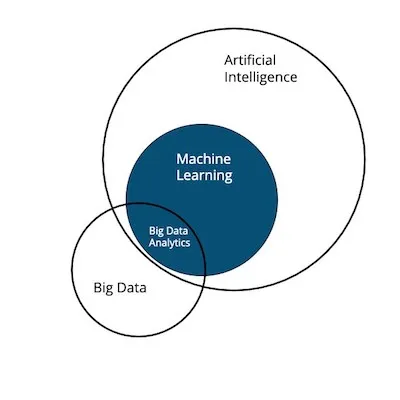
AI acts as a broader umbrella under which machine learning lives.
Big Data
Big data is a little easier to understand. Simply put, it’s a large volume of data collected from various sources, which contains a greater variety and increasing volume of data from millions of users. The more data and more variety, the better the accuracy of the Machine learning models trained on this data. Although more data is good, it is not useful if it does not contain variety.
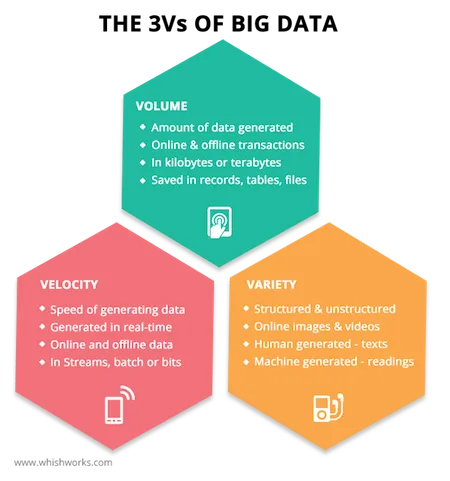
There are the three ‘Vs’ of big data, namely:
- Volume: In simple language, defined as the amount of data available.
- Variety: Variety in big data refers to all the structured and unstructured data that has the possibility of being generated either by humans or by machines. Variety is essential because it allows ML models trained on the data to be able to handle a wider range of predictions.
- Velocity: The rate at which data is received from other users and acted upon.
Usually, big platforms collect large amounts of data from user interactions in order to improve their services. Most of this data is encrypted and saved anonymously. However, there are downsides to these collections.
In recent years, there has been a major concern over privacy and security of user’s data. Most companies have now updated their privacy policies and imposed strict rules on data collection and have given more power to their users in deciding what can be collected.
Similarities
As stated earlier, ML, AI, and big data aren’t quite the same, but public perception relating to them is what sometimes creates confusion. This is because all three of them have one thing in common—they’re all data-driven technologies
To elaborate
Artificial intelligence is actually a broad concept involving machines making decisions based on machine learning models. In short, an AI is an application of ML.
Though it seems similar, machine learning has completely different criteria for carrying out tasks. We allow the machines to access the data and let them learn by themselves, and the outcomes are further analyzed.
The collection and storage of this data for future use by machine learning models are what can be defined as big data. This, in turn, provides room for variety, which is intended to prevent failures in the models trained on this data.
Applying these 3 technologies—together
Most big companies like Google, YouTube, Amazon, Netflix, Spotify, and many others constantly collect and analyze user interaction data with their platforms. They run machine learning models to predict user demand, taste, and other behavioral patterns.
For example, Google wants to provide you with the most relevant search results so that you never switch to another platform. Google’s own feature phone, the Google Pixel, has the best camera because it uses AI to improve the quality of the pictures. Forbes has an excellent article here that explains how the Google Pixel uses ML to capture the best photos. This AI is so good because it was trained on data Google got from a trove of images on the Internet.
Netflix, YouTube, and Spotify want to provide optimized recommendations for what to watch or listen to next. This is made possible because they’re constantly collecting data and learning your interests based on what content you’ve already viewed. This is all done by ML, and as previously mentioned, an application of machine learning is AI. Examples like these hopefully create a clearer picture of these terms in your mind.
Conclusion
When comparing AI, ML, and big data, we can observe that they seem to be interdependent, meaning that they cannot exist without each other. If one is taken out of the picture, then the others don’t have nearly as much meaning—or may not even exist.
The pace at which AI is advancing, some researchers predict that one day it may replace the human workforce completely.
However, the likelihood of eliminating humans is distant. As of now, the most advanced AIs are of the narrow AI type, which means they only excel at performing a single type of task, unlike humans who are smart and flexible enough to perform a large number of tasks with high accuracy.
Comments 0 Responses