
Phew, okay. After writing part 1 in this series looking deeper into the AI and machine learning landscape, I needed to take a deep breath.
I came across so many awesome companies, organizations, and tools for data labeling, generation, and preparation—it left me impressed but also with a key question in my journey: Now that we have all we need to prepare our datasets, what’s next?
Enter training. This is such a key part of the machine learning workflow—but it’s also something I knew little about. I’ve lived on the inference side of things during my time with Fritz, so jumping in to the model training landscape was a bit of an adventure.
Here’s another incredible list of tools and platforms—these are intended to take the labeled, pre-processed datasets from the platforms in part 1, and train them into production-ready machine learning models. Some of these tools include other awesome functionalities as well, so I’ll try to cover those, too. Let’s jump right in!
ClusterOne
ClusterOne is a training platform for deep learning that gives you the easy (and scalable) power to train your models on distributed GPUs and CPUs without setup or maintenance. They conceive of this platform as an “operating system” for deep learning. The have a number of different solutions, including cloud-based, on-premise, and even an SaaS platform for enterprise.
They also have a nice catalogue of content to help you get started and succeed with their platform, including webinars, a blog, and a Slack group. Here’s one webinar I particularly liked:
Databricks
Databricks is a unified analytics platform developed by the original creators of Apache Spark. Their platform has 3 elements:
- Workspace: The workspace enables the unification of data science and engineering, empowering easy model training and deployment. Compatible with all major/familiar tools, languages, and skills. Delivered via interactive notebooks or APIs.
- Runtime: The Runtime tool helps machine learners and devs prep clean data at-scale, while also continuously training and deploying ML models for various applications.
- Cloud Service: A fully-managed cloud infrastructure — the idea is to take the hassle out of developing and maintaining infrastructure complexity. Intended to keep data safe and secure while also allowing machine learning teams to focus more on innovating.
Databricks also organizes the Spark + AI Summit, an annual conference for the Apache Spark community.
DAWNBench
DAWNBench is a suite of benchmark for training (and inference) of deep learning models. This project comes out of Stanford and includes an interesting competition series, in which machine learners and data scientists can submit models in Image Classification (w/ ImageNet and CIFAR10 datasets) and Question Answering (SQuAD).
The suite measures the following benchmarks: training cost, inference latency, and inference cost across different optimization strategies, model architectures, software frameworks, clouds, and hardware. Here’s the summary of their first competition, which took place in 2018:
Hyperopt
Hyperopt is a Python library intended to help with hyperparameter optimization for ML algorithms and models. Specifically, there are two algorithms that are currently implemented with Hyperopt: Random Search and Tree of Parzen Estimators.
This project is largely hosted on GitHub, where you’ll find some really good documentation, tutorials, and more. Here’s a basic tutorial to help you get started:
Lambda Labs
Lambda Labs is a hardware/cloud infrastructure company that specializes in workstations, servers, laptops, and a GPU cloud built for deep learning. One particularly useful feature of all their equipment and services is that they all come pre-installed with every ML framework, from TensorFlow to Caffe2.
They also offer Lambda Stack, a software tool for managing the installations of new framework versions, upgrades, etc. They also have a nice blog with a mix of technical tutorials, benchmarks, company updates, and more. Here’s a cool one on implementing object detection with SSD in TensorFlow:
PaddlePaddle
PaddlePaddle is an open-source deep learning framework developed by Chinese tech giant Baidu. What sets PaddlePaddle apart is that it leverages Baidu’s distributed computing infrastructure, which allows for big savings on compute cost and the flexibility to train large-scale sparse models.
PaddlePaddle also has a neat visualization tool for deep learning that allows teams to observe training performance data. Additionally, they have a built-in education system with deep learning courses, an online dev tool, and in-person training sessions for Chinese developers, students, etc.
Here’s an example of a dynamic histogram, used to visualize parameter distribution:
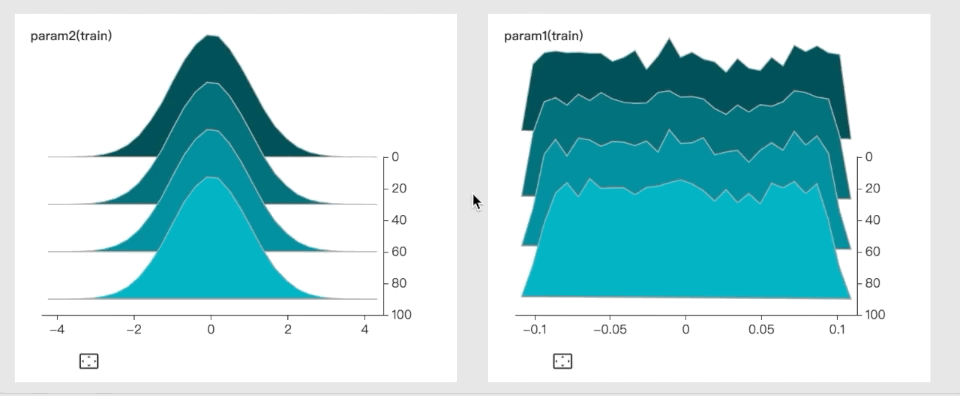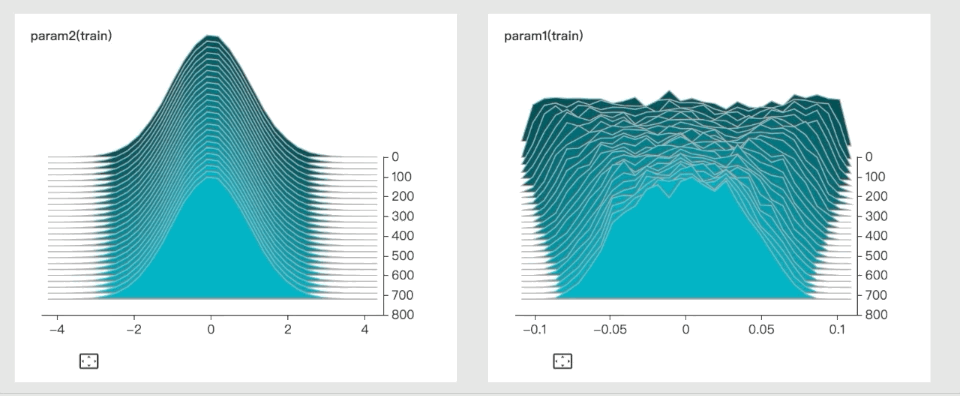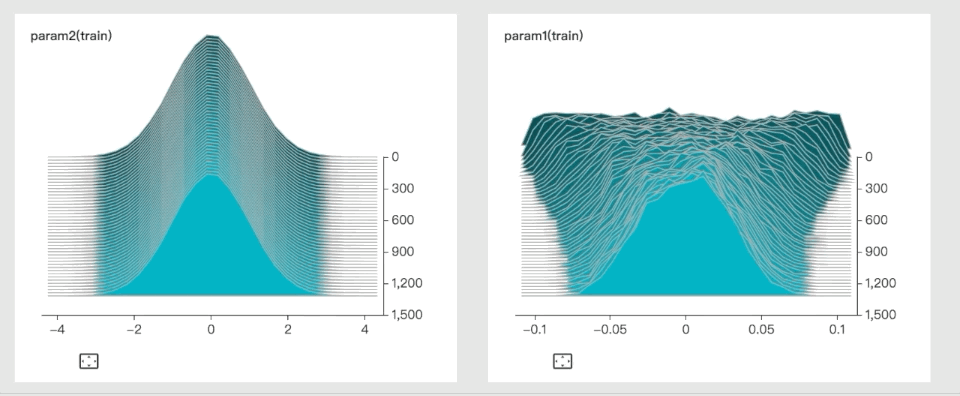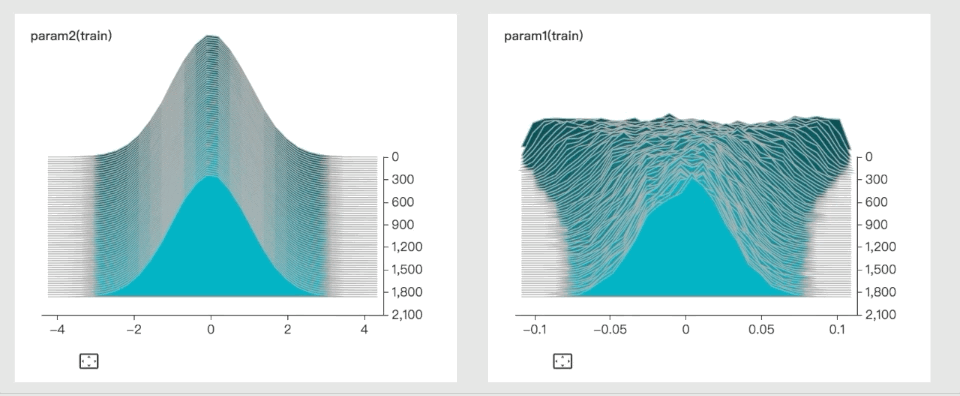
Paperspace
Paperspace is GPU cloud platform (w/ an API), intended to create and facilitate next-gen applications and cloud ML pipelines. The have 3 main products:
- Gradient — Branded as “Effortless infrastructure for Machine Learning and Data Science.” It’s a suite of tools for data exploration, neural net training, and executing GPU compute jobs. Inlcludes 1-click Jupyter notebooks and a Python module so you can run all your code on the Paperspace GPU cloud.
- Core — As the name implies, this is Paperspace’s primary tool. It’s their fully-managed GPU cloud platform for enterprise. Complete with a management interface, interconnectivity with existing networks, and a series of possible integrations.
- PaperspaceAPI: Paperspace’s toolkit for developers that will help automate various functions within your Paperspace account. Initially available in Javascript with more languages planned for the future.
Here’s a cool video introducing Gradient:
Trifacta
Trifacta is a data preparation and cleaning platform targeted at enterprise clients. Preparing and cleaning data is an essential step to ensure that your model is actually training based on your intentions. Their website accurately notes that “data today is messy and diverse,” and their tools work to empower analysts, engineers, and data scientists to prep data of any kind, no matter where it’s found.
Their Wrangler platform includes 4 primary features:
- Interactive Exploration — automated visualizations based on data content and context
- Predictive Transformation — every interaction with the Trifecta platform leads to a prediction. Every click, drag, or select assesses the data at hand and delivers a ranked list of suggested data transformations
- Intelligent Execution — Every step of the process is recorded and tracked automatically to help optimize the execution of data processing
- Collaborative Data Governance — Support for security needs, metadata management, and more. Allows flexibility in how organizations administer their data
Trifacta also has an extensive resource library, including webinars, user guides, videos, and more. Here’s one video I especially liked, which looks at how Tipping Point Community, a non profit in the Bay Area, used Trifacta and Tableau to fight poverty in the San Francisco area:
Yellowfin
Yellowfin is an integrated data analytics platform that, simply put, does a lot. Automated analysis, data storytelling, and collaboration tools and support. Most of these tools seem to be more adjacent to the training process. So while this isn’t a training platform per se, there are a lot of interesting things here that can be helpful at the training stage of the workflow. Here are their primary tools:
- Signals — “Discover what your dashboards are missing.” Automated dashboard analysis that sends personalized signals that show what data changes matter
- Stories — “Increase user adoption for your analytics tools.” Offers the ability to tell data stories across different areas of your organization
- Dashboards — AI-powered dashboards means that deliver key insights: What’s the right data to analyze? What are the most statistically-relevant results? This smart dashboard aims to answer these questions
- Data Discovery — A collaboration tool that helps visualize data insights to be shared across your organization. Findings here can be shared across the other tools
- Data Prep — Spreadsheets, Web APIs, databases; everything you’ll need to extract and prep data from various business sources
Yellowfin also has a handy blog that features company updates, industry analysis, and more. Here’s a good post that summarizes and discusses some of the why behind their suite of tools:
Discuss this post on Hacker News and Reddit.
Comments 0 Responses