
Pandas is an open-source Python library built on top of NumPy. Pandas is probably the most popular library for data analysis in Python. It allows you to do fast analysis as well as data cleaning and preparation. One amazing aspect of Pandas is the fact that it can work well with data from a wide variety of sources such as: Excel sheets, CSV files, SQL files, or even a webpage.
In this article, I will show you some tips & tricks to use in Pandas.
It will be divided into tips for:
- Generating data inside a Pandas dataframe.
- Data retrieval/manipulation inside the dataframe.
1. Data generation:
Often, beginners in SQL or data science struggle with the matter of easy access to a large sample database file (.DB or .sqlite) for practicing SQL commands. Wouldn’t it be great to have a simple tool or library to generate a large database with multiple tables, filled with data of one’s own choice? Fortunately, there exists a library that offers such a service—pydbgen.
What exactly is pydbgen?
It’s a lightweight, pure-Python library used to generate random useful entries (e.g. name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in either a Pandas dataframe object, as a SQLite table in a database file, or in a MS Excel file.
To install pydbgen, you need to have the Faker library installed. So just type:
- Pip install Faker
- Pip install pydbgen
To start using pydbgen, initiate a pydbgen object:
Generate a Pandas dataframe with random entries:
You can choose how many and what data types will be generated. Note that everything returns as string/texts. The first argument is the number of entries, and the second is the fields/attributes to generate fake data for.
This will result in a dataframe looking like this:
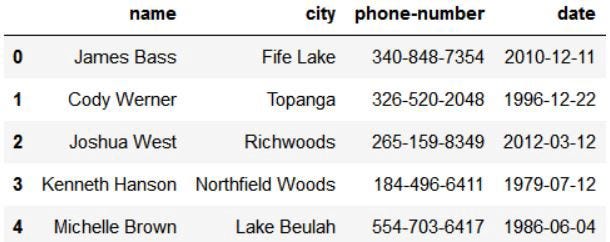
Of course, there are many more fields available, such as: age, birthday, credit card number, SSN, email ID, physical address, company name, job title, etc.
2- Dataframe manipulation:
In this section, I’ll show some tips for some of the more commonly-asked questions regarding Pandas dataframes.
For explanation purposes, I will be calling the dataframe “data”—feel free to name it whatever you want.
Retrieving data without knowing the index:
Usually with huge amounts of data, knowing the index for each row is almost impossible. So this method gets the job done for you. So in the “data” dataframe, we’re searching for the index of a row which has the user_id equal to 1.
Retrieving the row that corresponds to that index:
Pretty simple, right?
Getting all unique attribute values for a column:
So assuming we have an integer attribute called user_id:
Then you can iterate over that list or do whatever else you’d like with it.
Filling missing values for a column:
As with most datasets, one must expect A LOT of null values, which can be irritating at times. Of course, you can leave them as they are if you wish, but if you want to add values in place of null values, you must first declare what value will be put in what attributes (for its null values).
So here we have 2 columns called “tags” and “difficulty”. I want to put “MCQ” for any null “tags” value and “N” for any null “difficulty” value.
Getting a sorted sample from the dataframe:
Let’s say you want to sort a sample of 2000 rows (or even your entire dataframe) through an ID attribute. Turns out, this is pretty straightforward.
Grouping records using groupby:
What if you want to know, for each user/ID, the mean number of an attribute that they interacted with?
Let me demonstrate how to do this with an example. We have a history of users solving different problems with the scores, and we want to know the mean number of scores achieved by each user. The way to find this out is also relatively simple.
Conclusion
So by now, you should be able to create a dataframe and populate it with random data to experiment with it. This data will save you the hassle of finding a custom dataset.
Also, the data can be of any preferred size and can cover a lot of data types. Furthermore, you can apply some of the mentioned tricks to become more familiar with Pandas and realize how powerful of a tool it can be. Finally, I hope this article was helpful to you, and thank you for taking the time to read it.
Written By: Ahmed Yasser
Comments 0 Responses