
As a university student, I (and many of my peers) think a lot about exams. Sometimes I catch myself thinking: The human brain works 24/7 for 365 days, right from our birth, until…we step into the examination hall 🙂
How many times in your life you have wondered whether you will pass or fail an exam of some kind? Maybe you know more about yourself, your habits and tendencies, etc., so you can more accurately predict your result. But how many times you have wondered whether a friend of yours will pass the same exam or not?
How about predicting whether a few of your friends will pass an exam or not? This prediction should be based on some general facts you know about these friends. For example, the number of hours they study every day at home or the number of hours they’ve spent working with a tutor.
Turns out, we can use machine learning to predict whether or not a given individual will pass or fail an exam. More specifically, we can use use logistic regression to do this — one of the most classic and foundational predictive algorithms.

Implementing Logistic Regression
Let’s jump into an implementation and see if we can get a reliable prediction (before the exam results come). Some predictions, like this one, have no use after a certain period of time.
First things first, let us import the required Python libraries. In this case we’ll require Pandas, NumPy, and sklearn. We will be using Pandas for data manipulation, NumPy for array-related work ,and sklearn for our logistic regression model as well as our train-test split. We’ve also imported metrics from sklearn to examine the accuracy score of the model.
Load the data
At this point, we’re ready to load our data into a Pandas dataframe. To do this, we’ll use Pandas’ read_csv method, given that our data is stored in the .csv format on our local file system. You can download the data here.
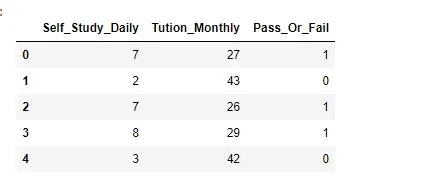
Note that the loaded data has two features—namely, Self_Study_Daily and Tuition_Monthly. Self_Study_Daily indicates how many hours the student studies daily at home, and Tuition_Monthly indicates how many hours per month the student is taking private tutor classes.
Apart from these two features, we have one label in the dataset named Pass_or_Fail. This label has two values—either 1 or 0. A value of 1 indicates pass and a value of 0 indicates fail.
After the data is loaded, our next step is to separate the features and label them as x and y respectively. Note that we’re using a drop method to drop the Pass_Or_Fail label and assign the rest of the columns to the x variable.
Next we port the Pass_Or_Fail column to the y variable:
Once the features and labeled are separated, we’re ready to split the data into train and test sets. This will separate 25%( default value) of the data into a subset for testing part and the remaining 75% will be used for our training subset.
At this stage, we’re ready to create our logistic regression model. We’ll do this using the LogisticRegression class we imported in the beginning.
Train the Model
Once the model is defined, we can work to fit our data. We’re going to use the fit method on the model to train the data. Note that the fit method takes two parameters here: variables x_train and y_train. We created these variables we created in some previous code using the train_test_split function.

Once model training is complete, its time to predict the data using the model. For this, we’re going to use the predict method on the model and pass the x_test values for predicting. We’re storing the predicted values in the y_pred variable.
Finding Accuracy
We need to find the accuracy of our model in order to evaluate its performance. For this, we’ll use the accuracy_score method of the metrics class, as shown below:

We found that accuracy of the model is 96.8 % . By accuracy, we mean the number of correct predictions divided by the total number of predictions.
Predicting Pass or Fail
Now that we’ve tested our model, we need to predict the pass or fail probability of a few of our friends. For this, we need to use, as input to the model, the features of one of our friends—First_Friend. Our First_Friend has Self_Study_Daily and Tuition_Monthly values as 4 and 38, respectively.
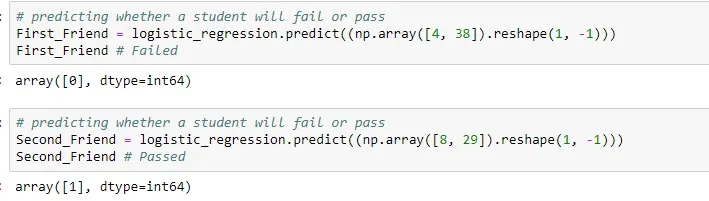
Note that we’ve used a NumPy array above to format the input so it can be passed to the model. Our model then returns the result in the form of an array having one value, either 1 or 0, where 1 indicates pass and 0 indicates fail.
End Notes
In this article we implemented logistic regression using Python and scikit-learn. We used student data and predicted whether a given student will pass or fail an exam based on two relevant features.
As a could of next steps, you might consider extending the model with more features for better accuracy. For example, you may consider a student’s grades from last year. I would encourage you to try different possibilities and share your findings in the comment section below.
Happy Learning!
Comments 0 Responses