
Computer systems have always been man’s best friend when dealing with intensive, computation-heavy mathematical problems. From simple calculations on a calculator to large statistical operations in R, this technological frontier has made life easier for a lot of us.
However, even computers are known to fault when numbers turn into letters and algebra starts getting involved. One might hope that with the advent of increasingly sophisticated machine learning and AI algorithms, this could be solved—but hopes and dreams continued to remain hopes and dreams…until now.
The good folks at Facebook AI recently released a research paper in which they ‘taught’ a computer how to solve differential equations using a method known as neural machine translation. However, reading an academic paper can be a tedious task for some, so here is a deconstructed version of what actually goes down in teaching symbolic mathematics to a computer.
What was the problem?
Neural networks have been around for quite a long time (since 1958, actually), and yet there hadn’t been any major developments in their application toward solving algebraic equations until recently.
You might wonder why, in this era of continuous research and breakthroughs, did it take so much time to achieve what seems to be a pretty easy task. However, as is the case with neural networks, nothing is ever as simple as it looks.
The above statement pretty much sums up the problem perfectly. Neural networks have always been used with statistical data, using different forms of pattern recognition to learn a given task.
Traditional pattern matching would allow a network to recognize that a particular arrangement of pixels should be classified as a dog, but it wouldn’t allow it to solve a multivariate equation. Solving complex equations would require more precision than generalization, which is just not what a neural net does.
Also, while solving equations, humans tend to have an “intuition” regarding how to approach a particular problem. We tend to have a rough idea of what the final solution may consist of, and our entire thought process is geared towards proving it. With no sense of intuition or foreknowledge, a computer system is essentially lost while solving a complex equation.
How the equation-solving AI was made
Let’s get into the nitty-gritty stuff and understand how researchers were able to achieve this previously-impossible feat.
Complex equations are considered a part of NLP (natural language processing), and thus, researchers were more inclined towards previously proven techniques in the field of NLP to tackle this problem. What followed was the genius of leveraging neural machine translation (NMT) to essentially translate the problems into solutions.
As strange as it sounds, the proposed method worked surprisingly well, with a significant increase in speed and accuracy when compared to algebra-based equation-solving software, like Matlab or Mathematicia.
Converting equations into sentences
NLP techniques are usually applied to words or a sequence of words to generate appropriate outputs. The NMT technique that the researchers decided to use for this problem was essentially a sequence-to-sequence (seq2seq) neural network.
A seq2seq model essentially takes in a sequence of words as input and outputs a sequence with some meaning imbued into it. Thus, to apply equations to a seq2seq model, the researchers first needed to convert them into sequences of words.
To achieve this, the researchers settled on a two-step approach. Initially, a system was developed which would, essentially, unpack the provided equations and lay them down in a tree-like structure.
This ‘tree-like structure’ was successful in giving a more accessible viewpoint to the symbolic equation, which would then be expanded into a form that could work well with the proposed seq2seq model.
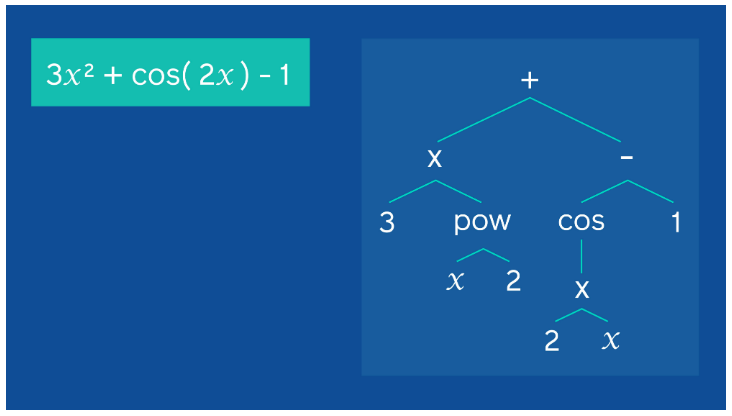
The structure of the tree was made such that the constants and variables became the leaves, while the operators acted as the internal nodes, which connected the different branches of the tree. Continuing with the equation-sentence analogy, the numbers and variables could be viewed analogous to nouns in a sentence, while the operators essentially act as verbs.
This approach helped the researchers to leverage a robust seq2seq NMT model, which was previously used for sentences and sequences of words; except that this time, the words were replaced with variables and operators.
Training the proposed model
Given that this is an entirely new approach towards solving equations through deep learning, a curated dataset for this specific purpose was unavailable. This was the first and foremost challenge when training the model—there’s simply no way to train a model without any data.
To ensure accuracy, the researchers decided to create their own dataset with specific problems that would ensure accuracy when the model was put to the test. An interesting (and rather frustrating) problem that came to light when curating the data was that since the equations were going to be eventually integrated (or differentiated), not all equations would have solutions. Thus, the dataset would need to be entirely novel, in terms of examples of solved equations restructured as trees.
An interesting observation noted by the researchers during data acquisition and accumulation was that, in the end, the dataset boiled down to problem-solution pairs, which showed a similarity to a corpus of words translated to other languages. The final training dataset comprised of millions of examples.
The next stage of the training process required applying this dataset to the proposed model. Thus, the dataset was trained on a seq2seq transformer model architecture, with eight attention heads and six layers. Transformers are generally used for translation tasks, and the network essentially translated problems to solutions.
Does the model actually work?
Now that you understand more about what’s going on under the hood, you might be wondering if a computer program can actually translate differential equations to their solutions. To test the model, the researchers provided it with 5,000 unseen equations (i.e. equations that were not part of the data that it was trained on) and forced the model to recognize patterns and solve the equations.

Results
When tested, the model demonstrated a whopping 99.7% accuracy for integral problems and 94% and 81.2% accuracy for first and second-order differential equations respectively, putting other traditional equation solvers to shame.
For comparison, Mathematicia achieved the next best results with 84% accuracy for integration based problems, while getting 77.2% and 61.6% accuracy on first and second order differential equations.The model also succeeded in giving the maximum predictions in 0.5 seconds when tested against other softwares, which took several minutes or timed out entirely.
An interesting observation made by Charton and Lample was that the model sometimes predicted multiple solutions for a single problem. Keeping in mind the translation approach on which it was developed, this made perfect sense, as there often exist multiple translations (with different meanings) for a given sequence of words.
Whats next?
The proposed model by Charton and Lample currently works to solve only equations of a single variable. But that isn’t what one has in mind when reading Whats next?
Sure, this work has given insight into ways neural networks can be applied in non-traditional ways. These evolving models are made to be resolute and smart, the two qualities that are advantageous in exposing blind spots in existing academic and practical approaches to mathematics.
This model proposed and achieved a task that was long considered impossible for a neural networks by applying NLP techniques in the wildest of ways. This research opens the gates to even broader perspectives and a larger amount of open-ended problems, which may end up being solved in a completely unorthodox ways by somebody just willing to take the risk.
Comments 0 Responses