
We’ve all heard the saying A picture is worth a thousand words. But is a tarnished image with gaping holes or splotches or blurs worth a few hundred? What if you just found an age-old photograph of your grandparents’ wedding, but the surface was so worn that you could barely make out their faces. Or perhaps you got photobombed in what would otherwise have been the perfect picture. Or maybe you’re like me and are wondering why hasn’t anyone integrated an option in a smartphone camera app to remove unwanted objects from images?

What is Image Inpainting?
This official definition of inpainting on Wikipedia already takes into account the use of “sophisticated algorithms” that do the same work of manually overwriting imperfections or repairing defects but in a fraction of the time.
As deep learning technologies progress further, however, the process of inpainting has become automated in so complete a manner that these days, it requires no human intervention at all. Simply feed a damaged image to a neural network and receive the corrected output. Go ahead and try it out yourself, with NVIDIA’s web playground that demonstrates how their network fills in a missing portion for any image.
Simply drag and drop any image file, erase a portion of it with the cursor and watch how the AI patches it up. I tried it on a few pictures lying around on my desktop. Here’s one of them below, with a big chunk of my face missing and the neural network restoring it again in a matter of seconds, albeit making me look like I just got out of a street fight.

You can also use it to quickly getting rid of something in a picture, too. Here’s another image I had lying around. A great view of Hangzhou’s west lake with the picturesque Leifeng Pagoda in the distance. The AI does a great job in envisioning a new lake with no pagoda around.

Traditional forms of image restoration usually evolve around some simple concept. Given a gap in pixels, fill the gap with pixels that are the same as, or similar to, neighboring pixels. These techniques are generally dependent on various factors and are more efficient for removing noise or small defects from images. They will most likely fail when the image has huge gaps or a significant amount of missing data.
The most straightforward and conventional technique for image restoration is deconvolution, which is performed in the frequency domain and after computing the Fourier transform of both the image and the PSF to undo the resolution loss caused by the blurring factors. The result of applying this technique usually creates an imperfectly deblurred image.

In a basic sense, inpainting does refer to the restoration of missing parts of an image based on the background information. It can be thought of as a process of filling in missing data in a designated region of visual input.
A New Approach with Machine Learning
The new age alternative is to use deep learning to inpaint images by utilizing supervised image classification. The idea is that each image has a specific label, and neural networks learn to recognize the mapping between images and their labels by repeatedly being taught or “trained”.
When trained on huge training datasets (millions of images with thousands of labels), deep networks have remarkable classification performance that can often surpass human accuracy. Generative adversarial networks are typically used for this sort of implementation, given their ability to “generate” new data, or in this case, the missing information.

The basic workflow is as follows: feed the network an input image with “holes” or “patches” that need to be filled. These patches can be considered a hyperparameter required by the network since the network has no way of discerning what actually needs to be filled in. For instance, a picture of a person with a missing face conveys no meaning to the network except changing values for pixels.
To enable the neural network understand what part of the image actually needs filling in, we need a separate layer mask that contains pixel information for the missing data. The input image then goes through several convolutions and deconvolutions as it traverses across the network layers. The network does produce an entirely synthetic image generated from scratch. The layer mask allows us to discard those portions that are already presented in the incomplete image, since we don’t need to fill those parts in. The new generated image is then superimposed on the incomplete one to yield the output.

A discriminator network, such as the one in a conventional GAN, can prove useful at such points. Its main use in such a scenario is to ensure that the final image obtained after filling in the gaps doesn’t look obviously fake. When compared with the original image, it needs to look reasonably similar, containing minute differences.
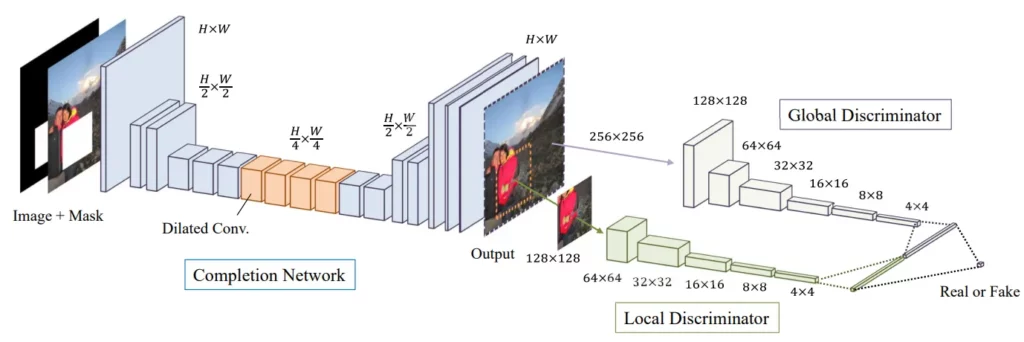
The problem here can be the absence of an original image to compare against. A discriminator network trained on thousands of image samples might be just the thing. Iizuka et al. propose a version of a network that can be used for image inpainting pictured below.
It consists of a completion network (for convolution and deconvolution) and two auxiliary context discriminator networks that are used only for training the completion network and are not used during testing. The global discriminator network takes the entire image as input, while the local discriminator network takes only a small region around the completed area as input. Both discriminator networks are trained to determine if an image is real or completed by the completion network, while the completion network is trained to fool both discriminator networks.
Not long ago, researchers at NVIDIA published a thesis on their new and improved method for inpainting irregular holes in images using partial convolutions. They claimed that previous approaches with deep learning focused on rectangular holes, usually around the image center, and often relied on expensive post-processing or “touching up”.
Their new method “operates robustly on irregular hole patterns, and produces semantically meaningful predictions that incorporate smoothly with the rest of the image without the need for any additional post-processing or blending operation.”
Their test results on the Celeba-HQ and ImageNet datasets (pictured below),demonstrate that their new method doesn’t suffer from the same drawbacks as previous approaches, which include some form of touch up to ensure the filled holes don’t look extremely fake. It also managed to avoid imperfections such as granular degradation or blurred edges.
Fundamentally, their method works by having the neural network create masks and partial convolutional predictions, thus generating an invisible, intermediate layer that can be controlled until the image passes its test of authenticity by the discriminator.

Image inpainting is a technique that has inspired widespread experimentation amongst enthusiasts. While there is always room for improvement, many tools and frameworks offer their own solutions for inpainting images.
OpenCV has two inbuilt methods for it. Both can be accessed by the same function, cv2.inpaint(), which simply needs a damaged image and a layer mask. The first is based on a Fast Marching Method, which starts from the boundary of the region to be inpainted and moves towards the epicenter, gradually filling everything in the boundary first. Each pixel is replaced by a normalized weighted sum of all the known pixels in its neighborhood.

Selection of weights is an important matter. More weightage is given to those pixels lying near the boundary of the missing parts, such as those near contours. Once a pixel is inpainted, it moves to the next nearest pixel using the Fast Marching Method, which ensures those pixels nearest the known pixels are inpainted first.
In simple words, a weighting function plays an important role in deciding the quality of the inpainted image. The distinguishing feature between weights being the amount of missing information.

The second method is based on a heuristic principle that encompasses fluid dynamics and partial differential equations. It first travels along the edges from known regions to unknown regions (because edges are meant to be continuous). It continues traveling along isophotes, which can be thought of as lines joining points with the same intensity, while matching gradient vectors at the boundary of the inpainting region.
You can also check out the Keras implementation of GMCNN (Generative Multi-column Convolutional Neural Networks) inpainting model originally proposed at NIPS 2018: Image Inpainting via Generative Multi-column Convolutional Neural Networks.
The model was trained using of high-resolution images from the Places365-Standard dataset, which can be accessed here.
Further Research
Inpainting images has always been a popular task that lures developers and researchers, as it’s a challenging task that can always been perfected further. Once deep learning was discovered to be a significant boost for improving inpainting algorithms, researchers also started exploring various other use cases and experiments that could be possible with the same approach and techniques.

SC-FEGAN
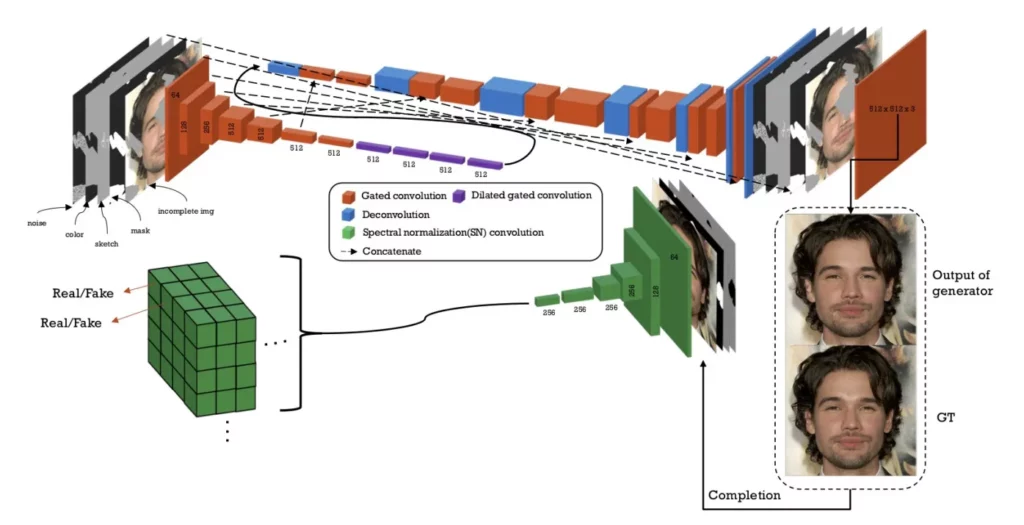
This idea was proposed in the research paper SC-FEGAN : Face Editing Generative Adversarial Network with User’s Sketch and Color. In simplistic terms, it uses the principle of a GAN to fill in the missing parts of images by the data it “imagines”.
We’ve already seen that we can use this ability to obliterate or “erase” specific objects from an image (and not just noise). SC-FEGAN goes a step further by allowing users to edit the parts of the image they want to modify, serving as more of an image editing system than just an inpainting network.
The user provides a free-form mask, sketch, and color as input. A trainable convolutional network utilizes these inputs as guidelines to generate the new image. In essence, the aim here is not to inpaint a defective image, but to intentionally damage an effect and use the GAN’s ability to modify the image as one sees fit.
EdgeConnect
Another example is EdgeConnect, which implements “Adversarial Edge Learning” to improve upon the imperfections left behind by traditional deep learning inpainting techniques.
It uses a two-stage adversarial model that comprises of an edge generator followed by an image completion network. The edge generator “hallucinates” (or renders its own imagination of) edges of the missing region (both regular and irregular) in the image, and the image completion network fills in the missing regions using hallucinated edges as a guide.
The model was trained and evaluated on Celeba, Places2, and Paris StreetView datasets, with the researchers demonstrating its success over previous methods, both quantitatively and qualitatively. The model, implemented in PyTorch and along with the code, is available here.

The reasoning is simple. When one looks at an image with huge missing regions, the human mind is powerful enough to relay the missing information in a mental representation of the completed picture. The edges of an object in the image help the most in relaying this perception, as they help us understand “what” the image actually is, and we can fill in the finer details later on.
One could argue that completing the edges in the missing part is essentially a battle half won. The model accepts input images with missing regions and computes edge masks. Edges already present are drawn using the Canny edge detector, whereas the edges supposed to be in the missing areas are hallucinated by the edge generator network.

Interestingly, the model can also be used as an interactive image editing tool, as shown above. As with SC-FEGAN, it’s possible to manipulate objects in the edge domain and transform the edge maps back to generate a new image. One such possibility is using separate complementary halves from two images as input and edge map respectively. The generated image appears to share characteristics of both images.
Pluralistic Image Completion
When some area in an image is missing, there can be multiple reasonable possibilities as to what can be filled in. Since we don’t use these methods for testing but for practical applications, it’s never possible to tell what should actually be filled in the missing region.

Most image completion methods produce only one result for each masked input. However, pluralistic image completion focuses on the generation of several diverse plausible solutions for image completion.
Conventional deep learning methods only reserve one ground-truth training instance per label, leading to minimal diversity. The pluralistic method goes about this in two parallel phases. One is a reconstructive phase that utilizes the only one given ground-truth to get an insight on missing parts and rebuilds the original image from this distribution.
The other is a generative phase for which this “insight” about missing parts is coupled with the newly rebuilt images to obtain potential fits or “spinoffs”. Both phases are undertaken by generative networks.
Conclusion
While it’s true that machine learning is the latest thing, it may not necessarily always be true that a machine learning approach outperforms conventional inpainting algorithms. The superiority of deep learning methods for image inpainting remains highly subjective from image to image.
Although it’s true that inpainting with deep learning works much better when the algorithm needs to be applied on a general category of images (i.e the kind of image is not known beforehand), it’s also probable that the growth in computational power as well as the introduction of newer and more powerful AI accelerators will eventually lead to perfectly inpainted images.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
Comments 0 Responses