
🎯 The above paper was published in 2019 at the International Conference on Machine Learning (ICML). On the ImageNet challenge, with a 66M parameter calculation load, EfficientNet reached 84.4% accuracy and took its place among the state-of-the-art.
EfficientNet can be considered a group of convolutional neural network models. But given some of its subtleties, it’s actually more efficient than most of its predecessors.
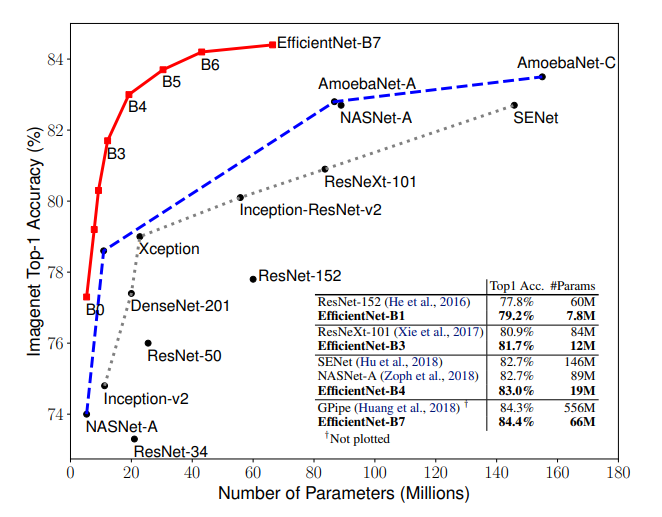
The EfficientNet model group consists of 8 models from B0 to B7, with each subsequent model number referring to variants with more parameters and higher accuracy.
So the question then becomes: What’s effective? We can see that the success of models on the ImageNet dataset has increased as they’ve become more complex since 2012. However, most of them aren’t effective in terms of processing load. In recent years, more efficient approaches have been adopted with smaller models. So much so that when scaling down the model, scaling is done on depth, width, and resolution—focusing on all three in combination has made for more effective results. Yes, effective 🤓.
Given this, the EfficientNet model architecture will have to scale in three stages!
❄️How EfficientNet Works
It.s possible to understand in three basic steps why it is more efficient.
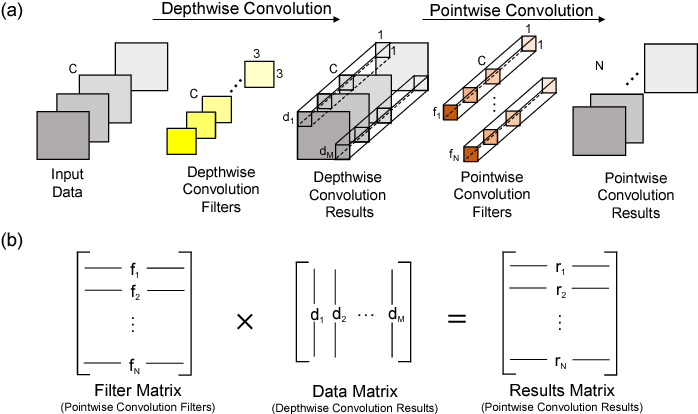
- Depthwise Convolution + Pointwise Convolution: Divides the original convolution into two stages to significantly reduce the cost of calculation, with a minimum loss of accuracy.
- Inverse Res: The original ResNet blocks consist of a layer that squeezes the channels, then a layer that extends the channels. In this way, it links skip connections to rich channel layers. In MBConv, however, blocks consist of a layer that first extends channels and then compresses them, so that layers with fewer channels are skip connected.
- Linear bottleneck: Uses linear activation in the last layer in each block to prevent loss of information from ReLU.
The main building block for EfficientNet is MBConv, an inverted bottleneck conv, originally known as MobileNetV2. Using shortcuts between bottlenecks by connecting a much smaller number of channels (compared to expansion layers), it was combined with an in-depth separable convolution, which reduced the calculation by almost k² compared to traditional layers. Where k denotes the kernel size, it specifies the height and width of the 2-dimensional convolution window.
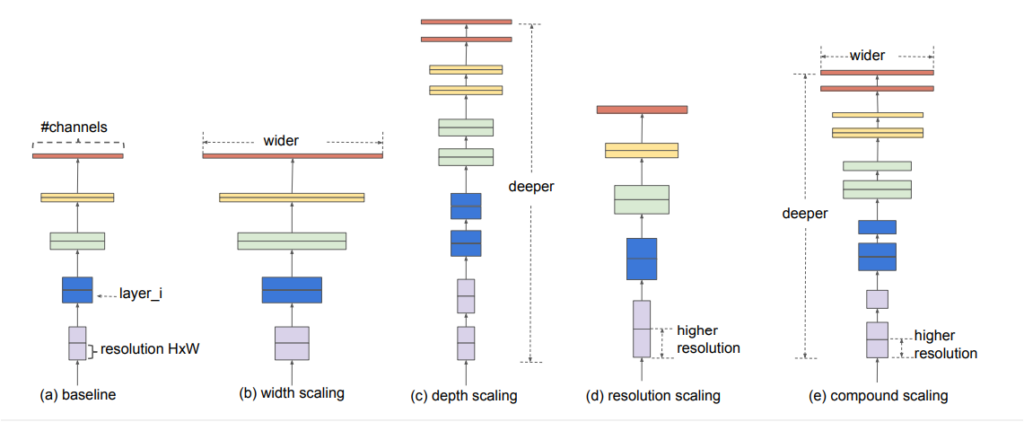
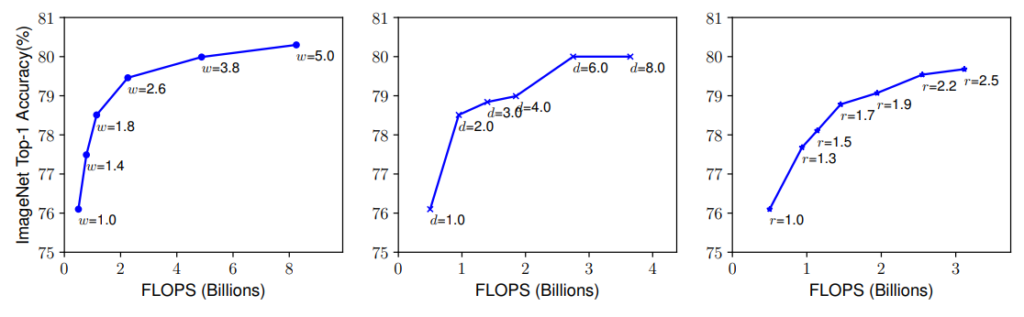
Larger networks with greater width, depth, or resolution tend to achieve higher accuracy. However, once the accuracy gain reaches 80%, it’s quickly saturated. This indicates the limitation of one-dimensional scaling. The individual scaling technique is called compound scaling.
If you want to increase the FLOPS 2-fold from EfficientNetB0 to EfficientNetB7 (to ensure that EfficientNetB1 has 2x FLOPS compared to EfficientNetB0), it’s necessary to take the following approach:
depth: d = α φ
width: w = β φ
resolution: r = γ φ s.t. α · β 2 · γ 2 ≈ 2
α ≥ 1, β ≥ 1, γ ≥ 1
❄️Creating an EfficientNet Model
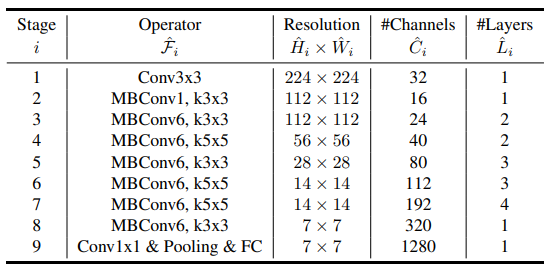
Step 1️⃣: Building a basic model is called EfficientNet-B0. MBConv is used with MobileNet’s inverted Res bottlenecks.
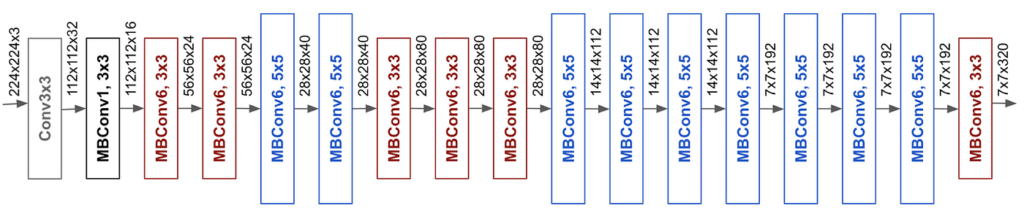
Step 2️⃣: ϕ = 1 and grid search for α, β, and to scale from B0 to B1.
Step 3️⃣: α,β,γ set. Thus, for scaling from B2 to B7, ϕ is selected between 2 ~ 7. Below, you can see class activation maps for models with different scaling methods.
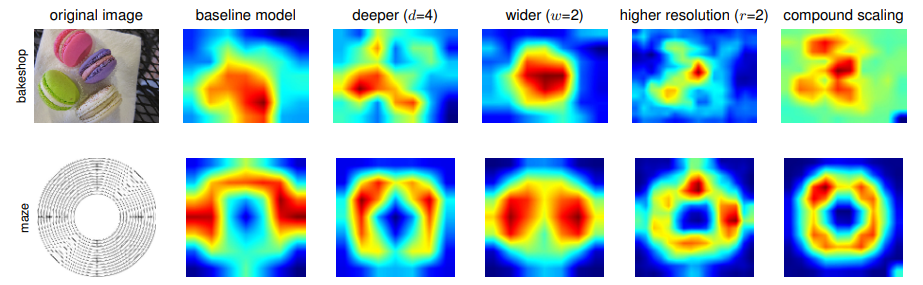
It appears that the compound scaling method focuses on details more efficiently in the object-related regions. Worth trying! 🤖
❄️The Effect of Transfer Learning on EfficientNet
For a moment, let’s take a small step back from the nitty-gritty details of EfficientNet.🕊Imagine that a bird could pass on to you what it has learned. Or what you have learned you could pass to a fish—sounds crazy, right?
Another way of saying this—I’ve learned since I was born and from my ancestors to recognize a glass. There are simple features (edge, corner, shape, material structure, etc.). Turns out, something happens when machines learn—they transfer what they know and learn to other machines, skipping the full learning process.
Pre-trained models are models that were previously trained and saved on a large dataset such as ImageNet. Thus, the features learned are useful for many new computer vision problems. However, these new problems may include classes that are completely different from the original task, and should not be ignored.
For example, an image can train a network on ImageNet (where classes are mostly animals and everyday objects) and then reuse this trained network for problems as disparate as identifying car models. However, in this case, you’d need different approaches specific to your problem in order to classify data that doesn’t exist in the ImageNet dataset.
We use pre-trained models only in applications where we want to test and predict only. For EfficientNet, transfer learning saves time and computational power, just like any other model. In doing so, it provides higher accuracy than many known models. This is due to clever scaling at depth, width, and resolution (as you read above). Let’s look at the accuracy and ratio of parameters for different datasets:
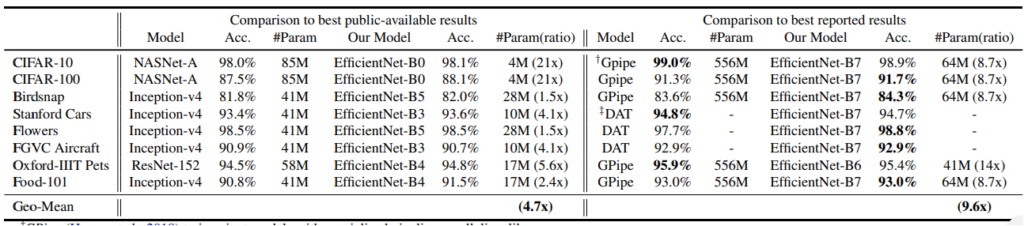
🌈 The EfficientNet Transfer Learning implementation is available through Google Colab — you can find the notebook in the GitHub repo below:
⚠️ In my review of this article, I emphasized that the successful results of convolutional neural networks are not directly proportional to the complexity of the model. Systematic scaling is one specific strategy discussed in the article, but research into building more efficient models continues. Thus, while performance continues to increase, positive progress has been made in terms of faster model speeds and smaller model sizes.
Why EfficientNet?
Models such as EfficientNet are particularly useful for using deep learning on the edge, as it reduces compute cost, battery usage, and also training and inference speeds. This kind of model efficiency ultimately enables the use of deep learning on mobile and other edge devices. In my opinion, it’s possible to reach these effective solutions with simple and clever mathematical transformations.
🌎This blog post has been translated from Turkish to English. Please visit here for the Turkish version of my article!
👽 You can also follow my GitHub and Twitter account for more content!
🎯 Additional resource: TPU Implementation of EfficientNet
Check out my other blog posts published on Heartbeat:
Comments 0 Responses