
In this post, I’ll be covering how CNNs are implemented efficiently in deep learning frameworks like TensorFlow and PyTorch.
When I was writing my own framework for Binarized CNNs in C++, I expected it to work as fast as PyTorch. The result — my Conv implementation was 100x slower than PyTorch. I even compared the number of FLOPs of my code with PyTorch. But the FLOP count was same.
After days of optimizing my C++ code, I realized it was slower because, in ML frameworks, convolutions aren’t implemented the same way we visualize them.
Even though, in this case, the FLOPs are the same, fetching data from memory is way slower and more energy-consuming when writing traditional convolutions. Actual convolutions are implemented after im2col kernel transformations through GEMM operations.
If you’ve never heard of these before, you have come to the right place. We’ll be demystifying them here.
But before getting into it, look at this table.
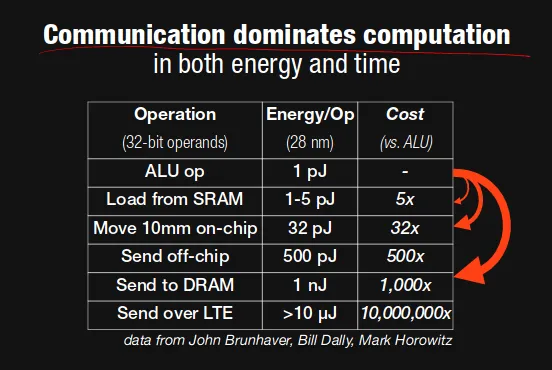
The interesting thing in the above table is that energy consumption of the ALU op (the part of CPU that performs computations) is 1000x less than data movement from DRAM. Processing time also has a similar trend.
Usually, to calculate processing time, we calculate the number of computations—but in data-intensive operations, communication (data movement) also plays a major role in the overall processing time.
As such, it’s not enough to just compute the data fast if we can’t get the data fast. Let’s start with some basics:
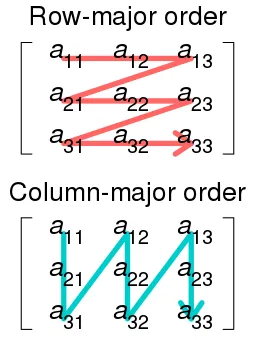
Data layout
A data layout defines how multidimensional matrices are stored in memory. For a 2-D array, it can either be in row-major or column-major order.
In row-major order, the consecutive elements of a row reside next to each other, whereas the same holds true for consecutive elements of a column in column-major order. The data layout is important for performance when traversing an array because modern CPUs process sequential data more efficiently than non-sequential data. This is primarily due to CPU caching.
CPU caching
The RAM can store a large amount of data, but because it’s off-chip memory, it’s fairly slow (i.e. high latency). CPU caches are orders of magnitude faster, but much smaller. When trying to read or write data, the processor checks whether the data is already in the cache. If so, the processor will read from or write to the cache instead of the much slower main memory. Every time we fetch data from the main memory, the CPU automatically loads it and its neighbouring memory into the cache, hoping to utilize locality of reference.
Locality of Reference
- Spatial locality — It’s highly likely that any consecutive storage in memory might be referenced sooner. That’s why if a[i] is needed, the CPU also prefetches a[i+1], a[i+2], … in cache.
- Temporal locality — It’s also highly likely that if some data are accessed by the program, they will be referenced again. That’s why recently used variables are stored in the cache after computation.
Convolution implementation
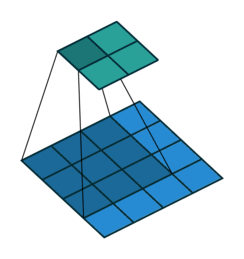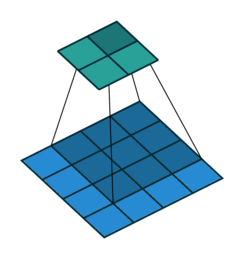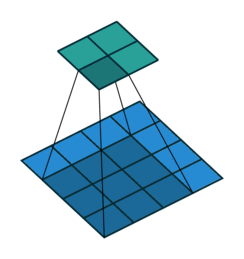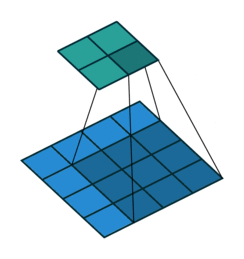
Now we have to optimize our convolution code in such a way that either the data recently used will be used again, or the data sequentially near that data will be used. Let’s first look at a traditional convolution operation:
for filter in 0..num_filters
for channel in 0..input_channels
for out_h in 0..output_height
for out_w in 0..output_width
for k_h in 0..kernel_height
for k_w in 0..kernel_width
output[filter, out_h, out_w] +=
kernel[filter, channel, k_h, k_w] *
input[channel, out_h + k_h, out_w + k_w]Let’s try to understand this by taking an example with an input image of shape (4,4, 2) and filter of shape (3,3, 2):
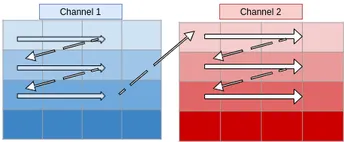
The above diagram shows how memory is accessed for the first window of the convolution operation. When we’re at (0,0), the CPU loads data not only for (0,0) but also for the next elements of the row in the cache. As such, it won’t need to load data from memory at (0,1) and (0,2) because these elements are already in cache. But when we’re at (0,2), the next element [i.e. (1,0)] is not in cache — we get a cache miss and the CPU stalls while the data is fetched.
Similarly, it keeps stalling at (1,2), (2,2), etc. So what im2col does is simply arrange elements of one convolution window in one row. Then, they can be accessed sequentially from the cache without misses. As a result, all 18 elements required for convolution are rearranged, as shown in the image below:

In our example, there will be four convolution windows. After converting all to im2col and stacking them, we get the following 2-D array:

As you can see, now we have 18×4=72 elements instead of 32 elements (as in the original image). This redundancy is the downside of im2col, but with the resulting performance difference, it’s all worth it.

After rearranging the image, we also need to rearrange filters (in practice, they’re already stored like this). Suppose we had 5 filters of (3,3,2)—in this case, each filter will be arranged into a single column of 3x3x2=18 elements. Then 5 of them are stacked to get the (18, 5) matrix.
At this point, we’ve converted this into a simple 2-D matrix multiplication problem. And this is a very common problem in scientific computing. There exist BLAS libraries like OpenBLAS, Eigen, and Intel MKL for computing GEMM (General Element Matrix Multiplications). These libraries have been optimized for many decades for matrix multiplication, and are now used in all frameworks like TensorFlow, PyTorch, etc.

The matrix multiplication of the input and filter give the resultant matrix of shape (4,5). This can be rearranged into a (2,2,5) matrix, which is our expected size.
Conclusion
Finally, after using im2col, I could get speeds only 2–3x slower than PyTorch. But this isn’t the end of the story. There are a few other algorithms that can help speed things up even more, like:
- Winograd Fast convolution — Reduces the number of multiplications by 2.5x on a 3×3 filter. Works well on small filters only, however.
- Fast Fourier Transformation — Improves speed only on very large filters and batch sizes.
- Strassen’s algorithm — Reduces the number of multiplications from O( N³) to O( N².807). But increases storage requirements and reduces numerical stability.
In practice, different algorithms might be used for different layer shapes and sizes (e.g., FFT for filters greater than 5 × 5, and Winograd for filters 3 × 3 and below). Existing platform libraries, such as MKL and cuDNN, dynamically choose the appropriate algorithm for a given shape and size.
Comments 0 Responses