
Computer scientists have been attempting to solve many different Natural Language Processing (NLP) problems since the time computers were conceived.
But the field become slightly stagnant around the 2000s, and did not gain traction again till the ‘Deep Learning’ boom that occurred during the last decade.
Of the many factors that helped build this traction was the spike in available textual data, thanks to the rise in the number of web and mobile applications.
Another was the development of generic deep learning tools, such as TensorFlow and PyTorch, that smoothed the process of developing new models and reproducing results elsewhere, which made it easy to pick up from where others left off.
Also, novel embedding techniques that were also based on deep learning models had an obvious advantage over classical techniques that did not capture sufficient similarities and underlying contextual relationships in natural languages.
All in all, the research environment became very fertile for novel and interesting approaches to emerge. And in this article, we are going to go over five NLP tasks, which may not be all that old, but definitely got a lot of focus in 2020, and for which state-of-the-art solutions are appearing all the time.
Table of contents:
How to Read this Article
Since it will not be productive to explain every concept that comes up, I will be including links to original works, surveys, and some articles that explain some of the methodologies discussed here, so make use of that if you find yourself curious about any of them. Also, before we go on, let’s have a quick refresher on two of the common terms in the field of NLP that will be relevant to this article:
- Language Models: A language model’s sole objective is to predict whether a sentence is part of a language or not. Similarly, it predicts whether a specific word is likely to follow a given sequence of words. In the case of statistical language models, the model assigns a probability to each word in the working vocabulary of the application. Naturally, non-statistical models also exist, but the former type is what is employed in deep learning applications.
- Word Embeddings: Simply put, word embeddings are continuous vector representations/mappings of words. The main goal of these embeddings is to reduce the dimensionality of textual data with minimal loss of contextual and semantic information. This is motivated by the need to alleviate the well-known Curse of Dimensionality. Last decade, embeddings produced by unsupervised learning neural networks have proved to be much more effective and efficient than classical methods, like SVD.
With that out of the way, buckle up! Here comes our first NLP task…
Named Entity Recognition (NER)
Let’s start with something light. NER revolves around detecting entities in text that represent unique individuals, places, organizations, objects, etc. This task is typically a subtask of another NLP task, like question-answering, which is explained in more detail below.
Knowledge-based systems were the norm back in the day when annotated training data was not in use. These systems make use of an exhaustive lexicon that is usually constructed and maintained by domain experts. Of course, this means that lexicons may be lacking and incomplete. In other words, they are as good as the experts who built it.
Those systems were generally very accurate for domain-specific applications. In the era of deep learning, annotated training data are used to teach models that either take a word or a character at a time. State-of-the-art models combine both kinds of input and achieve very good results with minimal expert knowledge. More about modern NER neural architectures can be found in this survey.
Neural Machine Translation (NMT)
Back in the day, basic rule-based statistical models were the norm when translating text. These systems were complex and heavily algorithmic due to the heavy processing and analysis of the input data, such as syntactic and morphological analysis. In addition, these systems required a lot of domain knowledge from the field of Linguistics, as that was critical in analyzing pieces of text more accurately.
And it does not stop there; one also needed to store whole dictionaries and lexicons of both the source and the target languages.
Sadly, they were not robust enough, and did not capture context well enough. That is why Statistical Machine Translation (SMT) came into play. SMT had been able to hold its ground until 2016, when Google and Microsoft abandoned it in favor of neural-based translators.
The main selling point of neural networks lies in how they obviate the need of complex processing of the input, and instead focus all the creative processes of system development on data engineering and model design.
One of the architectures that prevailed was the Encoder-Decoder architecture. Basically, you feed the word embeddings to an encoder that generates a context vector (or vectors in some approaches), thus encoding all the information in the text.
Afterward, a Decoder makes use of this vector(s) to produce the translation in the target language. Different types of recurrent layers have been used in this architecture, such as RNNs, and LSTMs, but they had their limitations when capturing long temporal dependencies present in the text.
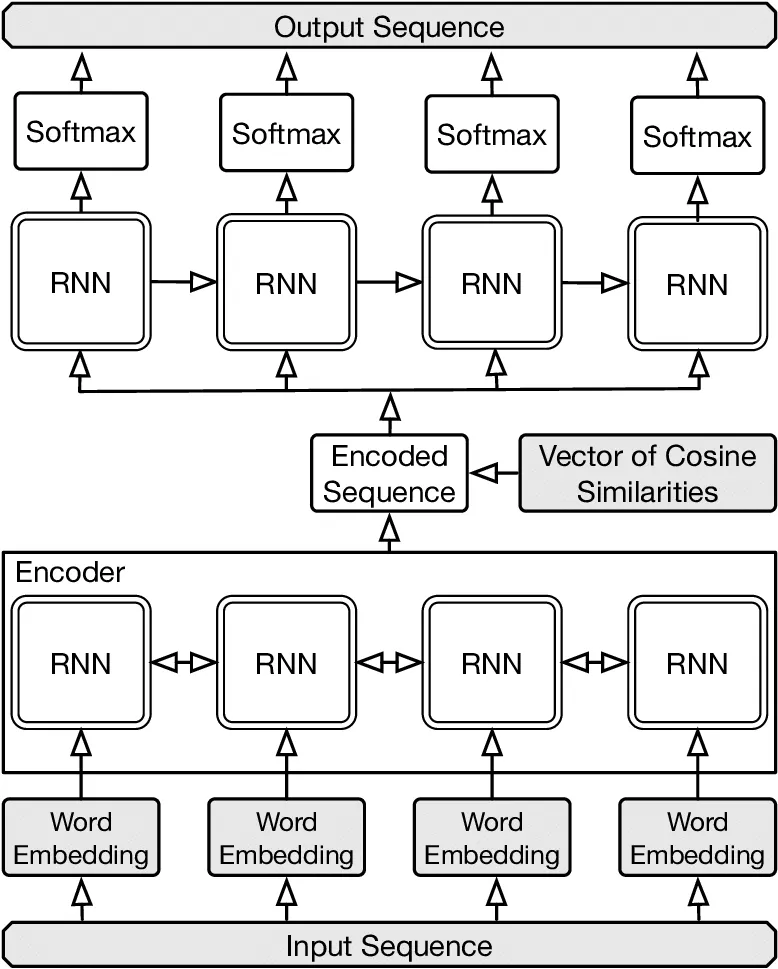
At the time of writing this article, Attention Mechanisms (such as the Transformer model [paper][explanation]) are achieving state-of-the-art results and are continuously getting better.
In a nutshell, instead of stuffing all the information into one context vector, attention mechanisms make use of all the vectors generated during the encoding and learn to pick the one most relevant in the current decoding step. This approach does not suffer from the temporal dependency problem as the other recurrent layers.
Sentiment Analysis
As the name suggests, this NLP task is about determining and guessing the sentiment present in text. One very common example of this is classifying the polarity of a piece of text in terms of how positive/negative it is.
The objective of this task can vary a lot from a case to another, but the simplest example would be analyzing the reviews of a product online to get an idea of the general outlook of the public on that product, without actually reading any of the reviews.
But it does not have to stop here. You can analyze sentiments relating to specific aspects of your product. For example, maybe you want to see if the design of the handle made your newly-released teapot more attractive and ergonomically-friendly. This is called aspect-based sentiment analysis.
But enough about the task! So again, linguistic-heavy approaches were used for this task, where a lexicon was constructed and built, containing a lot of sentiments and the respective words/phrases expressing each of them.
The input text would then be analyzed and examined with respect to the compiled lexicon to determine its sentiment. Now we can simply set up a dataset, and train a model on that.
Unsurprisingly, Attention Mechanisms also excel in this area, due to their ability to pay attention to the specific words or phrases that seem to directly correlate with the sentiment of a given piece of text, once properly trained. A review of DL techniques used in this area can be found here.
Text Generation
Many of us probably messed around with silly Chatbots when we were little, and some may have asked very tough questions to the bots to see if it would be able to reply. Of course, we would reach a point where we got nothing but weird, irrelevant replies from the bot.
Chatbots are an example of a group of NLP tasks related to text generation, where a language model has to generate text to satisfy a specific objective. Essentially, a general language model is fine-tuned according to the task in question.
Text Generation can span so many applications, from text summarization, to headline generation, and even to the generation of whole pieces of text, like articles!
Of course, generative models have been causing enough hype in recent years, due to their ability to generate faces of people who don’t exist, for example. But text generation can be slightly difficult to tackle using the same models due to the discrete nature of text.
But regardless of that, temporal generative models have been developed to generate text, mainly using the Variational Auto-encoders (VAEs) and Generative Adversarial Networks (GANs).
These architectures are built with temporal neural layers such as RNNs and LSTMs and are then trained on corpora, in either a supervised manner, or, sometimes, using Reinforcement Learning methodologies, until the loss is minimized. Several metrics have been proposed to evaluate generated text, and each has its own drawbacks and advantages.
Overall, the quality of generated text keeps getting better and people keep getting fooled by it. Recently, OpenAI released GPT-3, their latest generative model, which they claim produces state-of-the-art text, and makes use of a variation of the Transformer Architecture and few-shot learning techniques. Two exhibits of GPT-3’s text and feats can be found here and here.
Question Answering Systems (QAS)
QAS are a subset of text generation, but as the name implies, they are more focused on answering queries. QAS are about receiving a question about either a pre-determined domain (this is dubbed “closed domain QAS”), or something general (dubbed “open domain QAS”), and then answering this question correctly.
Rule-based and simple statistical approaches are also among the oldest paradigms that were used for constructing such systems, which would often have a knowledge-base (KB) containing a lot of the information about the domain (in case of open-domain systems, search engines are incorporated).
In the area of deep learning, Attention Mechanisms have been augmented into what is called Dynamic Memory Networks to achieve very competitive results, at the time of their publication.
More recently, a language model named BERT, developed by Google and also incorporating Attention, has been able to achieve state-of-the-art results on SQuAD, a question-answering dataset.
Visual QAS
Visual QAS is a form of closed-domain QAS that deals solely with images. You give the algorithm an image, and then ask it whatever you want about the contents of it: How many cars are there? Are there any elephants in the photo?
What color is the woman on the left wearing? But Visual QAS can even be extended to the problem of image captioning, where a model is required to generate a proper caption for the image in question.
A typical Visual QAS system would make use of a CNN — very likely pre-trained on a huge dataset like a VGGNet — to extract features from an image. Simultaneously, the question is analyzed and processed by a model, consisting of RNNs or LSTMs, for example, to extract the features of the question.
Both pieces of information are then combined and passed to the answer generator. The combination of the features can be as simple as a mere concatenation of the extracted vectors, or something slightly more complicated, like bilinear pooling.
So, what has helped researchers achieve gradually better results in this task? You guessed it, Attention Mechanisms! But what is different here is their application on images such that a model knows what region to focus on.
Evaluating models is more tricky when it comes to Visual QAS, as there can be more than one correct answer, either because of the varied nature of the content of the image or the possible levels of specificity.
Therefore, some works restrict the output of their models to a mere few words, usually between 1–3 per answer. This makes it easier to compare the results to ground truth, either by direct string matching or some similarity measure. If you are interested in knowing more about these challenges, check out this survey.
Conclusion
In this article, we went over several NLP tasks which had a boost in performance thanks to advancement in the field of deep learning. Obviously, there are many more tasks that are also getting their share of deep solutions.
It is apparent that we still have not hit our limit fusing deep learning and NLP together — the best example being the release of the GPT-3 model mentioned above. So, I hope this article made you even more curious about the field, and cause an indulgent need to contribute to it to arise!
Comments 0 Responses