
The Not Hotdog app from HBO’s Silicon Valley has become one of the most iconic joke apps in tech. Like most things in the show, there is grain of truth to the fictitious app that makes it actually plausible.
With Not Hotdog, HBO went a step further—they actually built the thing. If you ever need help to figure out if something is a hotdog, head over the app store.
Tim Anglade, a software developer for the show tasked with building the app, was kind enough to share his experience in a fantastic blog post. In just a few hours, he got a quick prototype working using Google’s Vision API, but for a variety of reasons he wanted everything to run on device.
Basically, it had to work in airplane mode. This seemingly simple requirement lead him on a circuitous several months journey that included help from the creators of TensorFlow.
It’s been 6 months since Tim’s post. This afternoon, using Apple’s new open source tool Turi Create, I was able build a simple Not Hotdog in about 3 hours.
I often hear about the breakneck pace of machine learning but today I felt it. If you’re a developer who has been waiting for the right time to join in, the bar has never been lower.
In the rest of this post, I’ll show you how to build Not Hotdog in a few hours, writing fewer than 100 lines of code. All you need is Turi Create and your laptop.
What is Turi Create?
Turi Create is a high-level library for creating custom machine learning modules. If you’re vaguely familiar with machine learning frameworks, Turi Create feels an order of magnitude simpler than Keras which feels an order of magnitude simpler than raw TensorFlow.
Under the hood of Turi Create is Apache’s MXNet, though you really can’t access any of it. Apple gives you the option of using a few pre-trained models and architectures, but nearly all of the parameters are inaccessible.
Finally, Apple has implemented some barebones data structures mirroring much of Pandas DataFrame functionality. I’m not sure why they decided to re-implement these from scratch, but they made good choices of method names and it feels quite natural if you’ve used Pandas.
One nice addition is an interactive GUI for visualizing data activated by calling the explore() method. Shown below is the interactive viewer I used to inspect images for this project. If you are doing a task like object detection, the visualization tool will even draw annotations like bounding boxes when available.
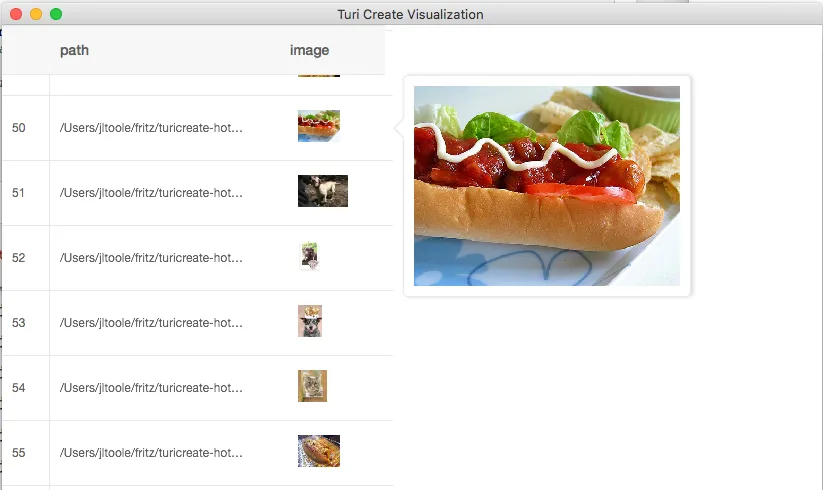
Installation
As with many machine learning tools, python is the language of choice. Apple has easy-to-follow instructions in the project’s readme. I’ll create a clean virtualenv and install with pip install turicreate. I’ve never used MXNet, but it appears that all the dependencies are installed just fine. I haven’t tried installing with GPU support, but that seems pretty easy, too.
Data Collection
Before I can start training a model I need data. I considered writing a scraper to crawl a few thousand results from Google Images, but then I found kmather37’s advice about using ImageNet to explore and download images in specific categories.
Simply type in a search term, click on the appropriate Sysnet category then in the Download tab click Download URLs of images in Sysnet. I’ll save the list of URLs in a text file for later.

I need two categories of images: “hotdogs” and…well…“not hotdogs”.
For hotdogs, I’m using the hotdog and frankfurter bun categories yielding a total of 2,311 images. For not hotdogs, I’m using categories plants, pets, buildings, and pizza, yielding a total of 8,035 images. The image URLs are saved, one per line, in two text files.
Next, I need to loop through the URLs and download the actual images. There are a couple edge cases and failure modes to work around, but I’ll spare you the details. You can have a look at the function I ended up writing in this gist:
import requests
import shutil
import os
def download_images(url_filename, out_directory, max_urls=None):
"""Download images from a file containing URLS.
The URL file must contain a single URL per line.
Args:
url_filename (str): a file containing urls
out_directory (str): a path to save downloaded images
num_urls (int optional): a maximum number of urls to try.
Useful for prototyping.
Returns:
errors List[str]: a list of urls that could not be downloaded
"""
img_idx = 0
url_idx = 0
errors = []
with open(url_filename) as urls:
for url in urls.readlines():
url = url.rstrip() # Remove the newline
try:
# Request the url and check the status of the response.
response = requests.get(url, timeout=2.0, stream=True)
if response.status_code != 200:
raise Exception('Not 200')
# Save the bytes to a file.
image_filename = os.path.join(
out_directory, '%05d.jpg' % img_idx
)
with open(image_filename, 'w') as out_file:
shutil.copyfileobj(response.raw, out_file)
img_idx += 1
except Exception as err:
errors.append(url)
url_idx += 1
if max_urls and url_idx >= max_urls:
break
print 'Tried %d urls and successfully downloaded %d images.' % (url_idx, img_idx)
return errorsIt’s important here to download images from each category into its own folder so that Turi Create can make labels for each. The two folders I’m using are hotdog and nothotdog.
Data Preprocessing
Any data scientist will tell you that data prep and cleaning is the most time consuming part of each project. Each image recognition model generally takes a slightly different image format, size, and preprocessing. I had expected to write a bunch of tips and tricks for data prep. Nope. Apple has baked all of those steps into training. All I need to do is load the data into Turi Create.
A few of the image files I downloaded were corrupt and Turi Create threw warnings, but it’s nothing to be concerned about. The argument with_path=True adds a path column to the resulting data frame with the absolute path of each image. I can now use a clever trick to create labels for each one of the training images:
That’s it. Training data cleaned and loaded. Just for fun, I decided to test out the groupby method on the data frame:
I lost about 25% of the images I started with. This training set could easily be augmented by creating variants with random noise, blur, and transformations, but let’s keep going for now.
Training
The first thing I want to do is split the data into a training set and a testing set for validation. Turi Create has a nice function for this:
Now it’s time to train. Training happens by calling classifier.create(). This threw me off initially because most ML / deep learning frameworks will initialize a model with random weights and require separate steps to compile, train, and evaluate.
With Turi Create, the create function does everything. The same function preprocesses the images, extracts features, trains the model, and evaluates it all. It’s really refreshing to work this way. There aren’t nearly as many configuration options compared with Keras, TensorFlow, or Caffe, but it’s so much more accessible.
By default, Turi Create will use ResNet-50 for its image classifiers. While ResNet provides great performance for it’s size, it’s a little over 100mb which is heavy for a mobile app. I’ll switch to SqueezeNet which is only 5mb, but sacrifices a bit of accuracy. After some experimenting, here is the create function I ended up with:
This took about 5 minutes to run on my 2015 15-inch MacBook Pro. I was really surprised at how fast training was. My guess is that Apple is using transfer learning here, but I‘ll need to look into the source to confirm it. Turi Create starts with the pre-trained SqueezeNet model. It analyzes your labels and recreates the output layers to have the proper number of classes. Then it tunes the original weights to better fit your data.
One thing I’d like to see added is the ability to start with an arbitrary model. For example, I started by training for a default 10 iterations, then decided to bump it up to 25. I needed to start from scratch and redo the first 10. It would be nice to simply continue where I left off with the model from the first training.
I was going to attempt to run things with a GPU, but honestly this was so fast I decided I don’t need to.
Here is the output from training:

Testing
Earlier I created a 20% holdout group of images for testing. Turi Create models have a convenient model.evaluate() to test the accuracy on full data sets. The results are pretty encouraging:

The last number is one to care about: 96.3% accuracy on the test data. Not bad for an hour of downloading images and 5 minutes of training!
Exporting
Turi Create can save two model formats: .model and .mlmodel. The former is a binary format readable by Turi Create (I suspect this might just be an MXNet file) and the latter is a Core ML file that can be dropped into your XCode project. It couldn’t be simpler:
The final .mlmodel file weighs in at a svelte 4.7mb.
Creating the Not Hotdog App
It’s time to fire up Xcode and put my model into an actual iOS app. I’m not a Swift developer so this part scares me the most. I’m able to get things working by changing a single line in Apple’s image classification example app (download it here).
Unzip the example project and copy the exported HotdogNotHotdog.mlmodel file into the Model/ folder, then add it to the Compile Sources list of the project. There might be a way to get Xcode to do this automatically, but I always end doing it by hand.

Now I need to swap my model out for the original. Change line 30 of the ImageClassificationViewController.swift file to:
That’s it! Time to build and test it out.

Final thoughts
Apple is changing… For decades, they have been laser-focused on high-end hardware differentiated by tightly controlled software. They’ve eschewed cloud services almost entirely and their best offering to developers is the monolithic 6gb Xcode, that never seems to be up-to-date on my machine. The rise of machine learning, and now deep learning, seems to be driving change.
Apple’s first and only blog is a Machine Learning Journal. Their last two open source projects have been coremltools and now Turi Create. Both make it easier for developers to get models into applications. These tools are still a bit rough around the edges, as Apple hasn’t had a lot of practice here, but I am shocked at how easy it was to complete this project.
If you’re a mobile developer who wants give your users magical user experiences that leverage deep learning, it’s never been easier. You no longer need a PhD in Artificial Intelligence or a math textbook to get started. I was able to build a “Not Hotdog” clone with in under 100 lines of code in afternoon. Kudos to all of the people working on these tools at Apple.
Comments 0 Responses