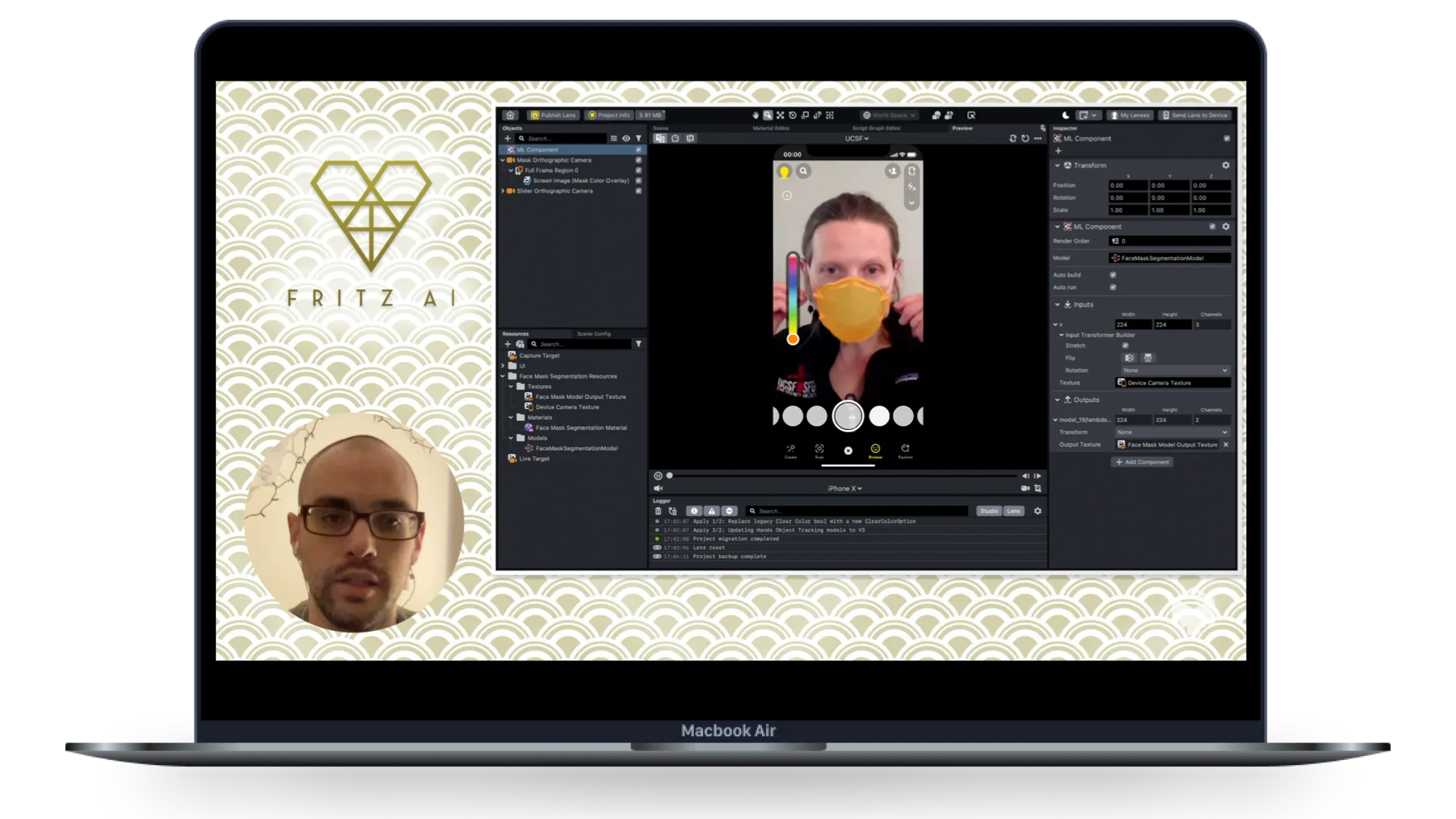
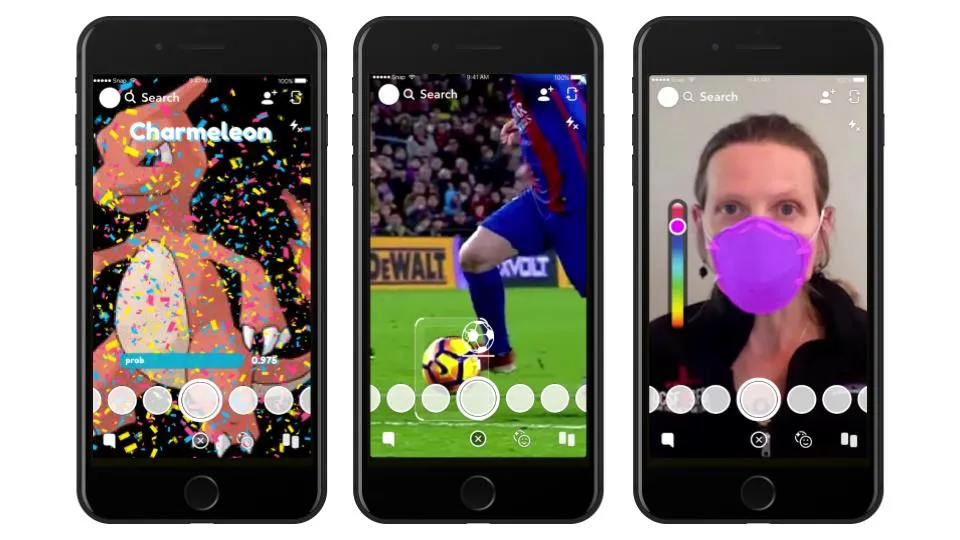
Machine learning unlocks a wide range of possibilities when it comes to AR development—nobody has proved that more than Snapchat, whose immersive augmented reality Lenses work so well in large part because of the ML models running underneath them (things like face tracking, background segmentation, and more).
With SnapML, though, Snapchat has opened up this expansive capability to its community of Lens Creators, allowing them to implement custom machine learning models in their Lenses.
Continue reading “Demystifying common use cases for SnapML in Lens Studio”