
Generative algorithms
Generative algorithms have opened a new window for AI applications. Machine learning has traditionally been concerned with classifying/learning the behavior of a certain process, without trying to mimic it, or more precisely; without generating a similar behavior.
We all witnessed the evolution of style transfer applications such as FaceApp, where a given image could be altered to generate different features such as beard, hair, age, or even smiles and laughs.
These generated features seem realistic to the user, which amplifies the fun factor. Another interesting example is thispersondoesnotexist.com. This website produces a purely machine-generated human photo every time you refresh it! Imagine viewing a person’s photo that’s magically photorealistic and synthetic at the same time. And strictly speaking, you’re the first and the only one to see this “machine synthesized” person.
Making machines creative
Examples of these amazing applications are becoming more numerous, ranging from generating still images, to videos (i.e. deepfakes), or even generating videos from still images. The good news is, now you can see the Mona Lisa nodding and laughing.
Machines are developing the capacity to create rather than just learn. And here’s where it gets interesting—what if we can teach machines to be creative? If they can create an image, then why not a painting? And if they can create a sound, then why not a pleasing sonata? And if they can generate a logical sequence of words, then why not poems, tales, and novels?
We’re in the age of machine evolution. Have you ever looked at a cubist or an avant-garde painting and said to yourself, this better be created by machines? The sharp lines, the hazy features—all characteristics of these artifacts. We humans of the postmodern era are more inclined towards abstraction. So why not let machines take the lead—they love abstraction!
Introduction to GANs
Warning! This is the “nerdy” part, but I think you’ll enjoy the genius behind it. Let’s assume you have two children in a room, and you want them to learn how to draw cats, but without direct involvement from you. So you give the first child, let’s call him a “discriminator”, an album full of drawings of cats, with different breeds and sizes.
And you give the second child, let’s call him a “generator”, random dots and shapes. So the generator hands the discriminator a drawing of his random album. Now you ask the discriminator to learn how to classify cats from non-cats and give his feedback to the generator by comparing his work against the cats’ album.
The generator, wanting to excel in his drawing skills hears the feedback and slightly modifies the random drawing to look more similar to whatever the discriminator is describing. He then asks the discriminator to reevaluate his work again.
This process repeats until the generator succeeds at deceiving the discriminator. This could take days or even months with human effort. But with the fascinating computation capabilities of machines, it shouldn’t take much time for the generator to fool his friend, the discriminator, into believing that the drawings do actually belong in the album of cats.
Data scientists call this a “Min-Max game”, as the generator, G, is always trying to maximize the probability of declaring fake data as real. And the discriminator, D, is trying to minimize that probability.
We can thus define what’s called the “objective function” of a generative adversarial network (GAN)—basically, the model’s objective. The objective function, in mathematical form, is concerned with both the probability of the discriminator classifying real input as real “D(x)” and the probability of the discriminator classifying fake inputs as fake “1-D(G(z))”.
In statistics, we like using log with probabilities in order to get a sense of the infinitesimal change happening between 0 and 1, or the probability range. So we “Logalize” the two probabilities and take the mean value over all the training period Ex~q(data). And let the game begin, as G tries to minimize the objective function, while the D tries to maximize it.
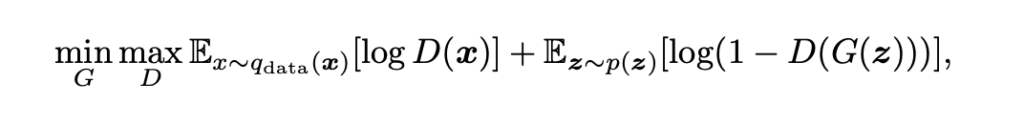
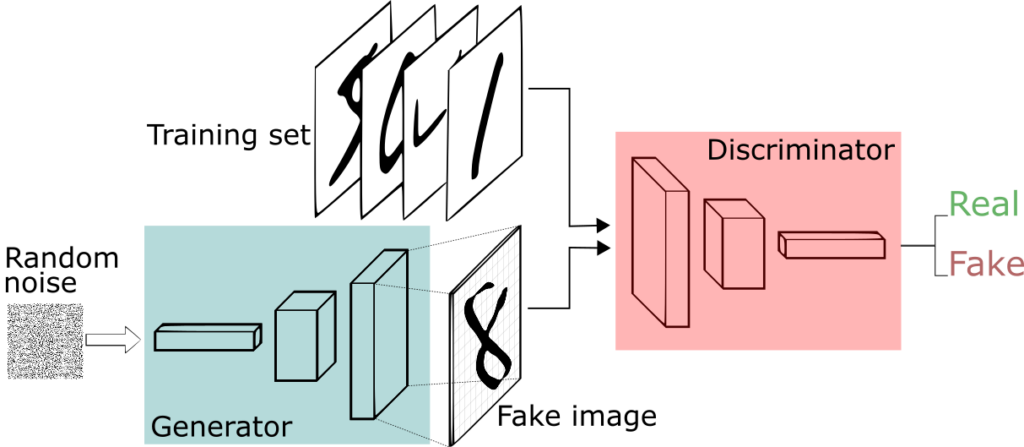
Now let’s dive into more of the deep learning details. Consider two neural networks, which consist of layers containing neurons. Each neuron fires only if the inputs surpass a certain threshold. This threshold is determined by a set of weights for each neuron. The task of deep learning is to find the suitable set of weights that would make the neuron fire, indicating the existence of a cute kitty face in the input—for example, only if the input was fed with such images.
Learning these weights requires two processes to occur. The first is forward propagation, where the current mixture of inputs and weights—initially random weights—result in a label. This label is to be measured against the actual label of the input image to find the error made by the network. This error, represented by what’s called a cost function, causes a drastic change in all the weights inside the network, encouraging it to perform well next time. This change is issued by the second process, backpropagation.

At this moment, knowing how a neural network roughly works, it becomes intuitive to think about the G, D Min-Max game as a war on the cost function.
The G adjusts his weights to minimize the error measured between real and fake data. Meanwhile the D tries really hard to spot this cheating process by modifying his weights to maximize the cost function. In more technical words, the G tries to capture the distribution of the real data in order to produce outputs, originally inputted as random values, that follow the same distribution.
GANs are the child of the genius mind of Ian Goodfellow. Goodfellow et. al. introduced GANs in the 2014 paper Generative Adversarial Networks. GANs, as shown, harness the well established discriminative models to tackle the main problems faced by generative models—thus achieving better results than these previous models.
GANs creating visual arts
In 2018, Christie’s, a British auction house, sold a GAN generated painting, “A portrait of Edmond Belamy”, for $432,500, along with the following artist’s signature:
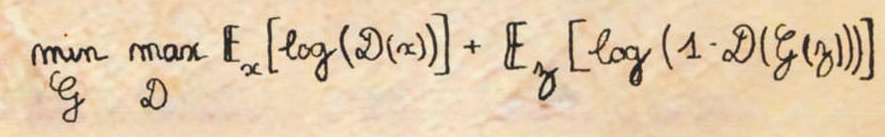
Do you recognize the artist? The signature belongs to our AI creative painter, GAN. It’s the GAN’s objective function we talked about earlier, performing the Min-Max game.

Edmond Belamy, to whom this portrait belongs, is a part of the Belamy family— all created with the GAN model.
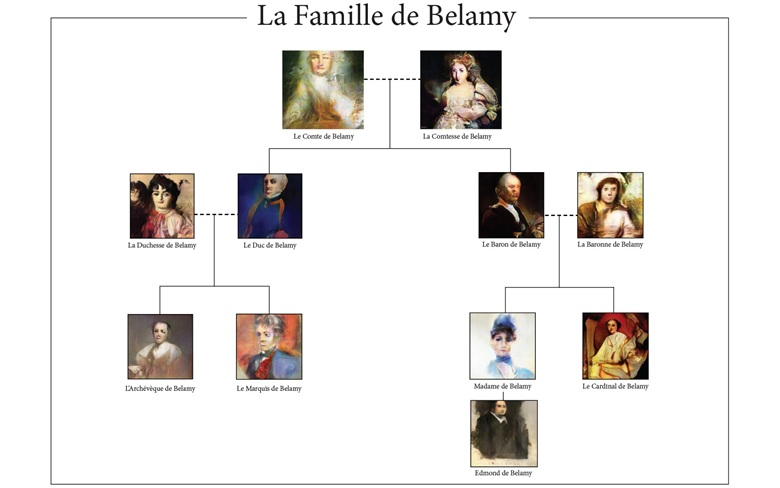
The generated portraits are stunning! It’s like artificial intelligence has its own Van Gogh. Well, it actually does. Kenny Jones and Derrick Bonafilia developed a fascinating project based on GANs—GANGogh, which include huge dataset of artistic works with different styles. The network then learned how to create paintings mixing those styles.

The project is based on a variation of GANs called DCGANs. DCGANs (deep convolutional GANs) build both the generator and the discriminator based on convolutional neural networks, which are discriminative algorithms mostly used for image classification.
The generated images are surrealistic with pleasing figures and color mixtures. I personally find them beautiful—perhaps with high artistic content that some might find expressive and relatable.
However, of all art generation algorithms, I find AICAN the most interesting. AICAN is an AI application based on creative adversarial networks developed by professor Ahmed Elgammal, the director of Rutgers university’s Art and Artificial Intelligence Lab.

These paintings are revolutionary! The fancy artistic style, the dream-like mood, the swaying lines and shapes, and the harmonic mixture of colors make them indistinguishable from contemporary human-created art. Elgammal has presented the works of his little creative artist, AICAN, in many art exhibitions.

More notably, the “Faceless Portraits Transcending Time” gallery, showcased portraits generated by the algorithm without any details given to their faces. You can check out a demo of their exhibition here. These promising results make the AI community a very exciting one with new adventures every once in a while. And they give us hope more interesting machine-generated art in the future.

GANs in music
For a generative algorithm, images might seem easy to generate. Sound, however, is a different kind of challenge because each sample heavily depends on the previous ones. It’s also important for the model to be able to generate a melody structure and a distinctive mode that depends on the relation between different tones and chords.
Hao-Wen Dong, et. al. proposed a model based on GANs that’s capable of generating musical tracks. In their 2017 paper, MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment, they introduced MuseGAN, which is fed with a dataset of over one hundred thousand bars of rock music. The generated phrases consist of bass, drums, guitar, piano, and strings tracks. A sample generated track linked in the paper shows us the performance of the model.
Overall, the results are promising and aesthetically appealing. However, the structure seems repetitive in a way that suggests that the generation process lacks novelty.
Training a generative algorithm for music generation is a hard task indeed, especially when you have different instruments with independent properties, such as percussion instruments, lead guitars, etc. Nonetheless, we shouldn’t give up on the enormous capabilities of GANs. AI engineers and data scientists are constantly working on enhancing these existing models, along with creating new ones.
GANs in literature
Like music, text generation requires the consideration of word sequence preceding each new addition. However, the task here is simpler, as the input—words—are easily discriminated, especially with the help of advanced NLP techniques and language models.
Text generation was lately associated with prohibition and the fear of AI threat. Same with almost every AI application; people always fear the spread of AI and the possibility of devastating consequences. When it comes to text generation tech, one should definitely mention GPT2. GPT2 is the invisible product of the AI team I love the most—OpenAI.
Last February, Open AI published a paper introducing the world to their amazing GPT2 language model, whose main mission is to predict the next word following an existing bit of human-written context. Hence, it can build an entire story starting from just a sentence! Here’s a sample they attached in the paper, where GPT2 is talking to us about four-horned unicorns with human origins.

Awesome, isn’t it? The generated text seems akin to what a news reporter might write. And that’s what makes it kind of scary! OpenAI realized this and decided to release the full model in four stages. Such a measure was taken in order to analyze the possible misuse of the model before being fully deployed. The latest stage presented a model with 750 Million parameters, while the full model is expected to reach 1.5 Billion parameters.
You can enjoy the amusement of the 750M model by visiting TalkToTransformer.com and type whatever comes to your mind. Of course, it’s not as powerful as the 1.5B one, but it’s still fascinating. Here’s a sample of my own trial:

I wrote the bolded text, and GPT2–750M completed the rest.
The core threat of text generation is hence obvious. The generated articles could be spread as fake news without having the slightest doubt about their authenticity. And the OpenAI team was confident enough to tell us that there’s no current machine learning algorithm with the ability to accurately discriminate real text from their fake one.
But hey, we’re only here for art! So let’s explore the possibility of making a poet machine—without worrying about these threats for now. Luckily, this field is producing some very good results that can ignite our excitement.
In their 2018 paper, “Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training”, Bei Liu et. al. presented an NLP-aided GAN that can generate poems from images. The algorithm takes clues from the image, mainly the description, and figures out a suitable compilation of poetic lines that fit these clues. The model has two “discriminator” blocks instead of one. The first checks if the generated poem suits the input image, while the second is responsible for checking the poetic authenticity of the poem.
In the paper, they attached a sample of a falcon image turned into a poem. In rhetorical terms, the generated stanza rhymes with pleasing consonance over the whole poem. The cool thing is that while keeping the poetic structure of the stanza, the words work together in a way that makes the whole text connected and meaningful.

Conclusion
Humans are the only creatures on Earth to evolve into thinking and creative beings. This has been true for the past thousands of years. AI, however, has emerged to rival such dominance. But instead of standing afar fearing the advancement of this technology, we can steer it towards creativity.
Although GANs are about 5 years old, with its first applications seeing light 2 years ago, they’ve showed a powerful capacity to turn machines’ internal 0s and 1s into pleasing artistic masterpieces. After all, art is what makes us truly humans. A piece of music can make you cry and a piece of text can make you laugh. You might even argue that art is life.
Let’s not go as far as Nietzsche when he said that “We have art in order not to die of the truth.” But we all can recognize the pivotal role art play in making us wake up every day. And I can imagine the future, where a personal AI can write you a specialized song attached with a piece of writing that matches your current psychological state. In that song, every pitch would matter, every pitch would be solely created for your mood. And in that poem, every word would a personal meaning that could hardly be shared.
Written by Abdulhady A. Feteiha.
Comments 0 Responses