
It doesn’t matter whether you’re a student, a researcher, a data scientist, a machine learning engineer, or just a machine learning enthusiast, you’re surely going to find PyTorch very useful.
As you might be aware, PyTorch is an open source machine learning library used primarily for applications such as computer vision and natural language processing.
PyTorch is a strong player in the field of deep learning and artificial intelligence, and it can be considered primarily as a research-first library.

Lets’s take a look at the top 10 reasons why PyTorch is one of the most popular deep learning frameworks out there
1. PyTorch is Pythonic
Python is one of the most popular language used by data scientists. When I use the term “Pythonic”, I mean that PyTorch is more attached to or leaning towards Python as its primary programming language. Perhaps not coincidentally, Python is also one of the most popular languages used for building machine learning models and for ML research.
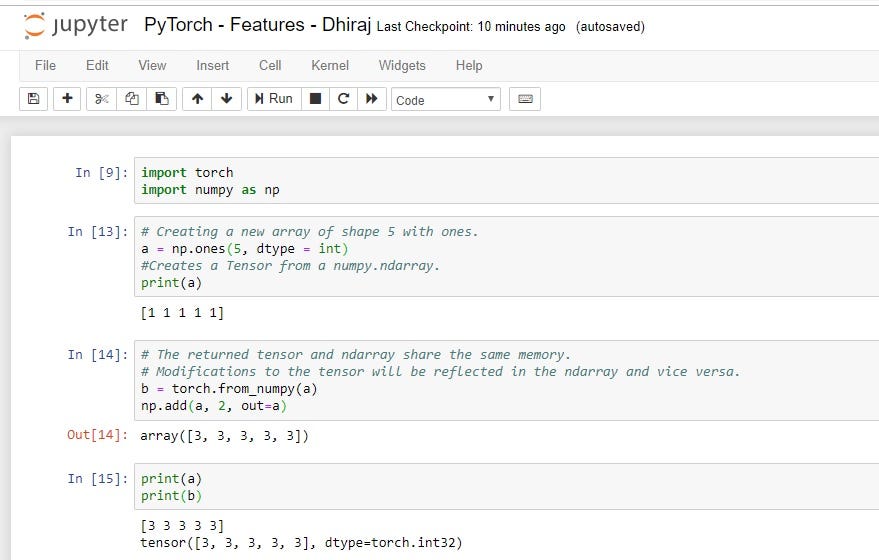
PyTorch is built to be seamlessly integrated with Python and its popular libraries like NumPy. Check out the code snippet below to see how easy it is to manipulate a NumPy array using PyTorch:

2. Easy to learn
PyTorch is comparatively easier to learn than other deep learning frameworks. This is because its syntax and application are similar to many conventional programming languages like Python.
PyTorch’s documentation is also very organized and helpful for beginners. And a focused community of developers are also helping to continuously improve PyTorch.
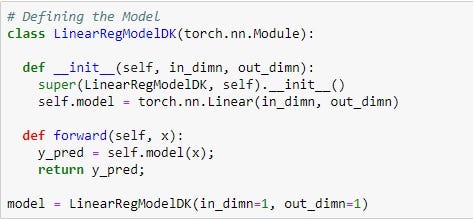
As you can see above, defining a machine learning model in PyTorch is as easy as defining a class in Python, with just a few methods.

3. Higher developer productivity
PyTorch is very simple to use, which also means that the learning curve for developers is relatively short.
PyTorch has a simple Python interface and provides a simple yet powerful API. PyTorch can also be easily implemented on both Windows and Linux.
PyTorch is easier to learn as it is not a completely different syntax for someone coming from programming background. The code below demonstrates that general programming practices like implementing variables, random numbers, square, and multiplication syntax are all very intuitive.

4. Easy debugging
As PyTorch is deeply integrated with Python, many Python debugging tools can also be used in PyTorch code. Specifically, Python’s pdb and ipdb tools can be used for this kind of debugging in PyTorch.
Python’s IDE PyCharm also has a debugger can also be used to debug PyTorch code. All this is possible as a computational graph in PyTorch that’s defined at runtime.
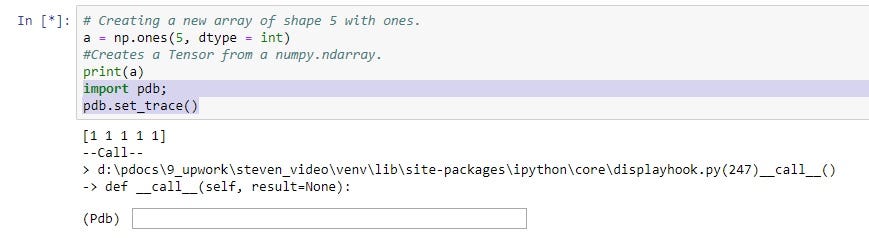
If you’re getting error in your code, you can start debugging by placing breakpoints using pdb.set_trace() at any appropriate line in your code. Then you can execute further computations and check the PyTorch Tensors or variables and nail down the root cause of the error.

5. Data Parallelism
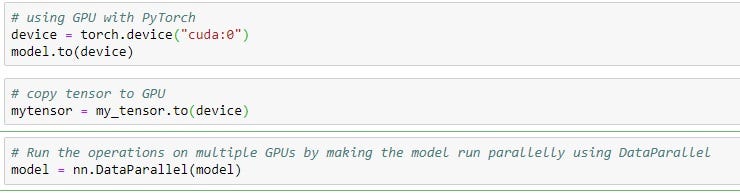
PyTorch has a very useful feature known as data parallelism. Using this feature, PyTorch can distribute computational work among multiple CPU or GPU cores.
This feature of PyTorch allows us to use torch.nn.DataParallel to wrap any module and helps us do parallel processing over batch dimension.

6. Dynamic Computational Graph Support
PyTorch supports dynamic computational graphs, which means the network behavior can be changed programmatically at runtime. This facilitates more efficient model optimization and gives PyTorch a major advantage over other machine learning frameworks, which treat neural networks as static objects.
With this dynamic approach, we can fully see each and every computation and know exactly what is going on.
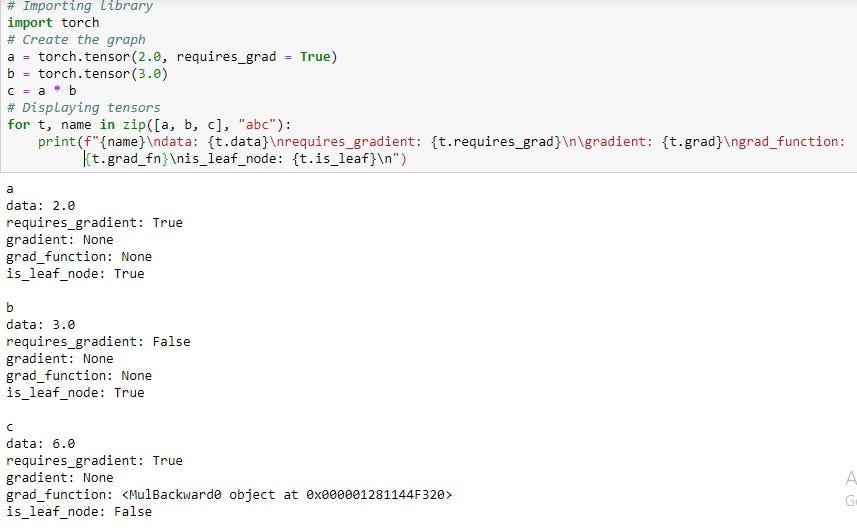
When the flow of data and the corresponding operations are defined at runtime, the construction of the computational graph happens dynamically. This is done with the help of autograd class implicitly, as shown below:

7. Hybrid Front-End
PyTorch also provides a new hybrid front-end. This means we have two modes of operation, namely eager mode and graph mode.
We generally use eager mode for research and development, as this mode provides flexibility and ease of use. And we generally use graph mode for production, as this provides better speed, optimization, and functionality in a C++ runtime environment.

8. Useful Libraries
A large community of developers have built many tools and libraries for extending PyTorch. The community is also supporting development in computer vision, reinforcement learning, and much more.
This will surely bolster PyTorch’s reach as a fully-featured deep learning library for both research and production purposes. Here are a few examples of popular libraries:
- GPyTorch is a highly efficient and modular implementation with GPU acceleration. It’s implemented in PyTorch and combines Gaussian processes with deep neural networks.
- BoTorch is a PyTorch-related library for Bayesian optimization.
- AllenNLP is an open-source NLP research library, built on PyTorch.

9. Open Neural Network Exchange support
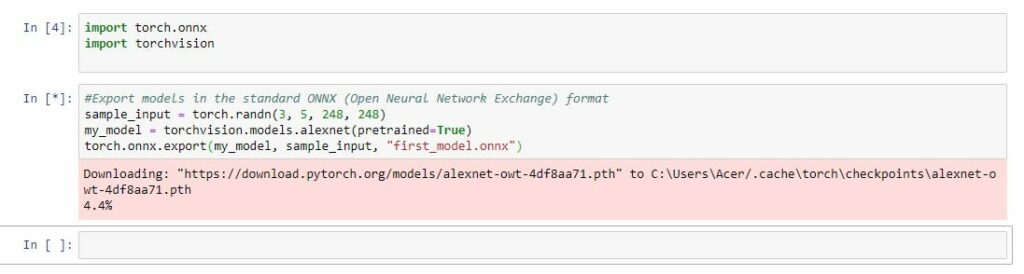
ONNX stands for Open Neural Network Exchange. With ONNX, AI developers can easily move models between different tools and choose the combination that work best for them and their given use case.
PyTorch has native ONNX support and can export models in the standard Open Neural Network Exchange format.
This will enable PyTorch-based models to direct access the ONNX-compatible platforms and run-times.

10. Cloud support
PyTorch is also well-received by major cloud platforms, allowing developers and engineers to do large-scale training jobs on GPUs with PyTorch.
PyTorch’s cloud support also provides the ability to run models in a production environment. Not only that, we can also scale our PyTorch model using the cloud. For example, you can use the below code to work with PyTorch using AWS Sagemaker.


Concluding Thoughts
We now have ten strong points to support our decision to select PyTorch as our preferred deep learning framework.
I would also like to mention that PyTorch provides excellent community support with a highly active developer community as well.
I hope these points will motivate you to try building a machine learning model using PyTorch.
Happy machine learning!! 🙂
Comments 0 Responses