The past, present, and future of AI-accelerated hardware for mobile machine learning
We’ve previously explored some of the core benefits and values of embedding machine learning models on-device and inside mobile apps. On-device machine learning models offer:
- Lower Latency: Because model predictions are made on-device, no device-to-cloud data transfer is required. Thus, models running on-device are capable of processing data streams in real-time, speeding up key UX components (i.e. processing live video).
- More Security and Privacy: With on-device AI, data doesn’t need to be sent to a server or the cloud for processing. This closed loop offers end users more control over who sees their data, when, and how.
- Increased Reliability: Sending data to the cloud for processing also requires an active and reliable internet connection. This is a significant barrier to access for remote and developing areas of the world.
- Reduced Cost: Avoiding heavy data processing between devices and the cloud can also be a huge cost-saver.
- More Immersive User Experiences: Complementary technologies like augmented reality, when combined with mobile ML, offer opportunities for new kinds of brand engagement, content creation, and other fine-tuned user engagement features and experiences.
These benefits have been hard won through decades of research to improve model accuracy and efficiency and incredible improvements to the hardware they run on. Today, 3.7 billion devices are capable of running on-device models.
This guide will explore the past, present, and future of AI-accelerated hardware for mobile machine learning.
Table of Contents
- Part 1: Why We Need AI-Accelerated Hardware for Mobile ML
- Part 2: The Evolution of AI-Accelerated Hardware
- Part 3: Today’s AI-Accelerated Hardware
- Part 4: Implications and the Future of AI-Accelerated Hardware
Part 1: Why We Need AI-Accelerated Hardware for Mobile ML
No matter how accurate or optimized a machine learning model is (yes, even if it’s the state-of-the-art), when it comes to performance on mobile devices, there’s a consistent limiting factor—the power of the hardware inside devices themselves.
The particular piece of hardware that makes this cutting-edge technology is a new class of processor that’s foundational to accelerating the performance of machine learning models: neural processing units, or NPUs. NPUs are AI-dedicated processors that are changing the rules for what’s possible when deploying neural networks on-device.
When we run machine learning models to make predictions (inference), this can require—depending on the model and task at hand—immense calculations that are both compute and memory-intensive. If we have plenty of powerful cloud-based CPUs and GPUs to perform this heavy data processing (and lots of money), we can push algorithms to their limits.
But when the deployment target for a machine learning model is a smartphone, we don’t have those kinds of seemingly limitless resources. These personal devices are inevitably resource-constrained, have limited battery capacity, and can’t cater to models that are gigabytes in size.
We can already run pretty powerful and accurate neural networks on-device with CPUs (and sometimes GPUs). But to really capture the undeniable promise and potential of on-device machine learning across industries, chip and smartphone manufacturers have had to team up in recent years to develop chipsets that are custom-made for running advanced neural networks.
This is essentially the equation: to truly enable intelligent, real-time experiences on-device—like tracking human movement, accessing virtual product catalogs, reproducing real-world scenes in 3D, AR-powered “try-on” features, and much more—hardware manufactures will need to continue to push the limits of what’s possible with AI-first chipsets.
But as with many things, a quick look back will help us see the present more clearly and envision the future with more foresight. So let’s take a trip down memory lane, and explore how we got here.
Part 2: The Evolution of AI-Accelerated Hardware
NPUs are the latest evolution in the processor family tree. Its older siblings, CPUs (Central Processing Units) and GPUs (Graphics Processing Units), have been the core processing components in all kinds of computer systems for decades.
As you can see in the timeline below, new evolutions of processors don’t come along once every couple of years. Branches of the processor tree tend to evolve through optimized architectures and improved manufacturing processes over decades. This implies that we’ve only just entered the era of the NPU, and we should see these AI-dedicated processors evolve in similar ways.
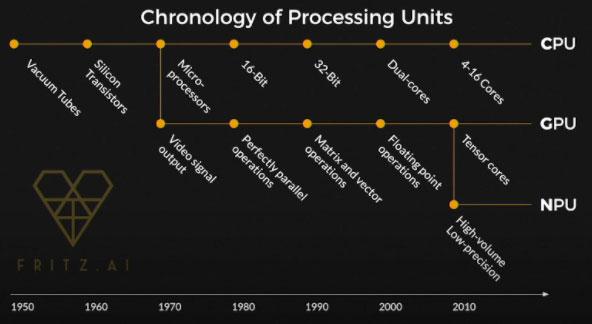
You could fill bookshelves exploring the ins and outs of this timeline, but there are a few key details about this chronology:
CPUs
CPUs (Central Processing Units) were designed as part of the Von Neumann architecture, first built in 1950 along with the ENIAC, the very first general purpose digital computer. From there, CPUs went through a series of evolutions: to silicon transistors, 8-bit, 16-bit, 32-bit, and finally into parallelism with additional processing cores.
CPUs work by storing values in registers—programs running on CPUs tell the Arithmetic Logic Units (ALUs) to read from these registers and perform given operations. This results in a lot of processing time spent moving in and out of registers.
GPUs
GPUs (Graphics Processing Units) split off from the CPU branch in the 1970s in order to focus on video output, but over time they became more general purpose. Specifically, GPUs became optimized for performing parallel matrix and vector operations on display pixels. While GPUs have helped increase AI processing speeds, they essentially still serve as a “hack” for running deep neural networks—in other words, they aren’t purpose-built to perform these intensive computations.
NPUs
Relatively recently, Neural Processing Units split off from the GPU branch, focusing on those same kinds of parallel operations but optimized for high-volume and low-precision workloads. Specifically, NPUs are built to facilitate the movement of data back and forth through a neural network, while also converting floating point numbers to fixed integer operations (high-volume via backward and forward propagation; low-precision via quantization).
While CPUs and GPUs can handle this kind of data processing, they aren’t as efficient in doing so as NPUs. As a reminder, NPUs are purpose-built for artificial intelligence. These are the processors that make ML-powered applications possible on mobile devices.
For more on the difference between these three processing units, check out this recording of Dan Abdinoor’s conference presentation at the 2019 ADDC conference in Barcelona.
Part 3: Today’s AI-Accelerated Hardware
According to a recent report from Counterpoint Research, 75% of all smartphones will have dedicated AI chips by 2022, signaling that the technology promises to become increasingly available (and powerful) as we move neural networks to the edge.
At the time of publication of this guide in mid-2020, there are a wide range of NPUs powering everything from microprocessors to autonomous vehicles. But to help narrow our focus, in this section, we’ll explore the NPUs inside today’s most popular—and most AI-capable—mobile devices.
Apple: The A13 Bionic and the Neural Engine
We’re now a couple of generations in, when it comes to Apple’s hardware commitment to on-device machine learning. Starting in 2017 with the A11 Bionic chip and its dedicated co-processor (the NPU) dubbed the “Neural Engine“, the iPhone has seen rapid advancements in its AI-by-design hardware.
The latest iteration—the A13 Bionic—includes a 6-core CPU (split into two groups of cores: Thunder and Lightning) and a 4-core GPU, with a capacity of running up to a trillion 8-bit operations per second. The runtime is based on Core ML, Apple’s framework for on-device machine learning
Meanwhile, the Apple Neural Engine (the NPU) is a special 8-core co-processor capable of accelerating machine learning models to run up to 9X faster using just a tenth of the energy. It’s the classic formula: faster speeds with lower power consumption (20% increase and 15% reduction, respectively).
Google: Pixel 4 Neural Core
Prior to the Pixel 4, the only thing resembling AI-dedicated hardware in Google’s flagship mobile devices was what they called the “Visual Core“, which was essentially a very powerful image processor that led to some incredible advances in computational photography…but it wasn’t exactly purpose-built for running a wide range of neural networks.
That changed with the Pixel for and the introduction of the “Neural Core“—designed in-house by Google which includes Google’s proprietary Edge TPU (Tensor Processing Unit). The Edge TPU is, as its name suggests, purpose-built for edge computing and can run up to 4 trillion ops per second. The Neural Core runs on top of a Snapdragon 855 chipset (Qualcomm), and it’s runtime is based on TensorFlow Lite, TensorFlow’s framework for edge-ready models.
It’s also worth noting that the Edge TPU is designed to power ML on other non-smartphone edge devices, like Raspberry Pi, Coral Dev Boards, and more.
Huawei: Kirin 990
Huawei’s Kirin 990 made a lot of headlines for its purported 5G capabilities, but its take on the NPU is equally if not more impressive (more, if you ask us). The 990 saw Huawei move away from contracting out AI processing to external chip architectures, and towards their own internal NPU architecture: “Da Vinci”. Its two primary cores support both 8-bit and 16-floating point quantization methods, a step up from previous Huawei NPUs which split processing power between the two techniques.
In addition to the two primary cores, the Da Vinci NPU also added what Huawei calls a “Tiny Core”, which is dedicated to non-critical processing operations. And according to Huawei, the NPU is incredibly flexible, optimized for up to 90% of the most common computer vision neural networks.
Part 4: Implications and the Future of AI-Accelerated Hardware
Implications
NPUs promise to revolutionize more than just mobile apps. From autonomous vehicles, to context-aware smart homes, to real-time try-ons for clothes or bicycles or golf clubs—the possibilities for dedicated AI hardware are endless. This is especially true given how early we are in the lifespan of NPUs, and how lightning fast recent progress has been.
But smartphones provide a particularly compelling case as the devices that will lead the way into this new era. Numerous reports and sources estimate that there are more than 5 billion mobile devices in the world, with about half of those being smartphones. The sheer quantity of smartphones in circulation, combined with the rapid progress we’ve seen in AI-dedicated chipsets in recent years, means we might just hit that estimate we mentioned earlier—75% of smartphones with AI-dedicated hardware by 2022.
With these capabilities in the hands of more than a billion people around the globe, the imperative becomes clear. Companies across a wide variety of industries, from retail to healthcare and beyond, will need to invest in this cutting-edge technology. With more powerful hardware comes the potential for more dynamic, responsive, and personalized mobile apps—apps that have the potential to increase brand engagement and loyalty, provide more immersive user experiences, and drive revenue.
The Future
When you give software developers more memory, more compute resources, or hardware that accelerates various processes, it’s fair to assume that they’re going to use these increased capacities. In other words, we can largely assume that software workloads will continue to expand, filling the computing resources available.
What does this assumption mean for the ways in which AI-dedicated hardware will impact the future of mobile app development? For one, the range of possible use cases will continue to expand—more immersive augmented reality experiences enhanced by on-device AI, more accurate scene geometry, an increased ability to tailor mobile experiences to individual users, and the development of applications that likely haven’t even been dreamed up yet.
But beyond the specific experiences AI-accelerated hardware will allow developers to build, there’s an entire ecosystem of software tools and frameworks that will evolve to meet the demands of AI-first development. Here are a few examples of this ecosystem evolution:
Automated machine learning (AutoML)
While AutoML isn’t technically a brand new approach to training ML models, its application to mobile and other edge devices is. Essentially, AutoML refers to (perhaps unsurprisingly) the process of automating ML workflows from end-to-end—from collecting and labeling data to managing models in production.
Often, AutoML solutions offer built-in data annotation tools, no-code model training options, and tools for monitoring model versions. For mobile projects, new automated workflows like Google’s AutoML Vision Edge and Fritz AI also offer built-in model conversion, data augmentation, and other mobile-specific optimizations.
These layers of abstraction promise to help development teams more effectively capitalize on the rapid improvements being made in device hardware. In turn, they will also enable increasingly powerful mobile ML experiences.
On-device model training
For our money, this is one of the most important pending developments in the mobile ML space. As mobile hardware capabilities expand—and as they become more centered on being purpose-built for AI workloads—we should begin to see on-device model training take center stage.
Currently, the vast majority of ML model training happens server-side—mobile devices themselves don’t yet have the hardware capabilities to actually train neural networks. However, that’s quickly changing, and we can expect to see on-device training become increasingly important for mobile ML solutions.
We saw our first taste of the possibilities of this with Core ML 3, Apple’s most recent version of their mobile ML framework. Simply put, the newest version of Core ML enables training simple neural networks (i.e. binary classification models) directly on the device—no interaction with a centralized server required.
This revolutionary change could dramatically reduce costs and project development lifecycles, while also leveraging data directly from devices to build models that are more responsive, personalized, and optimized for a given user. Emerging techniques like federated learning also promise to make the notion of on-device training more realistic and accessible over time.
And while the abstraction of the software layer(s) matters, the hardware inside the devices themselves matter as much, if not more. Alongside chipsets that have more processing power dedicated to AI-related computation, we should also see an increase in techniques enabling on-device training, which could further revolutionize what’s possible with mobile ML.
Cross-platform solutions
In recent months, both iOS and Android have added mechanisms for accessing additional processing power (i.e. Apple Neural Engine, Pixel 4 Neural Core) when running model inference on mobile devices.
However, one of the difficulties in accessing these hardware accelerators is the fractured landscape of devices across platforms. For instance, if you build a Core ML model for iOS that takes advantage of the Neural Engine, you’ll only see the improvements on a limited number of devices, and you won’t see them at all on Android.
The above example highlights the problem of building consistent cross-platform experiences across device generations. In some ways, we’re still in an in-between space in this regard. Development frameworks often silo experiences on a single platform (Core ML → iOS only), and even so, certain operations and model layers remain incompatible with AI-accelerated hardware.
And even though TensorFlow Lite (TensorFlow’s mobile/edge flavor) now enables cross-platform deployment, TFLite models on iOS aren’t as performant as their Core ML counterparts. Even if they manage relative parity in performance, it’s still somewhat unlikely that those models will be able to access accelerated hardware.
But as we see AI-dedicated hardware become the norm, on both flagship iOS and Android devices, we should also see increased software support for actually accessing these AI-dedicated chipsets.