
Federated learning is a new way of training a machine learning using distributed data that is not centralized in a server. It works by training a generic (shared) model with a given user’s private data, without having direct access to such data.
For a deeper dive into how this works, I’d encourage you to check out my previous blog post, which provides a high-level overview, as well as an in depth look at Google’s research.
Federated learning has the major benefit of building models that are customized based on a user’s private data, which allows for better customization that can enhances the UX. This, as compared to models trained by the data aggregated at a data center that are more generic and may not fit the user quite as well. Federated learning also help save a user’s bandwidth, since they aren’t sending private data to a server.
Despite the benefits of federated learning, there are still ways of breaching a user’s privacy, even without sharing private data. In this article, we’ll review some research papers that discuss how federated learning includes this vulnerability.
The outline of the article is as follows:
- Introduction
- Federated Learning Doesn’t Guarantee Privacy
- Privacy and Security Issues of Federated Learning
- Reconstructing Private Data by Inverting Gradients
Let’s get started.
Table of contents
- Introduction
- Federated Learning Doesn’t Guarantee Privacy
- Privacy and Security Issues of Federated Learning
- Privacy Protection at the Client-Side
- Privacy Protection at the Server-Side
- Security Protection for the Federated Learning Framework
- Reconstructing Private Data by Inverting Gradients
- Conclusion
Introduction
Federated learning was introduced by Google in 2016 in a paper titled Communication-Efficient Learning of Deep Networks from Decentralized Data. It’s a new machine learning paradigm that allows us to build machine learning models from private data, without sharing such data to a data center.
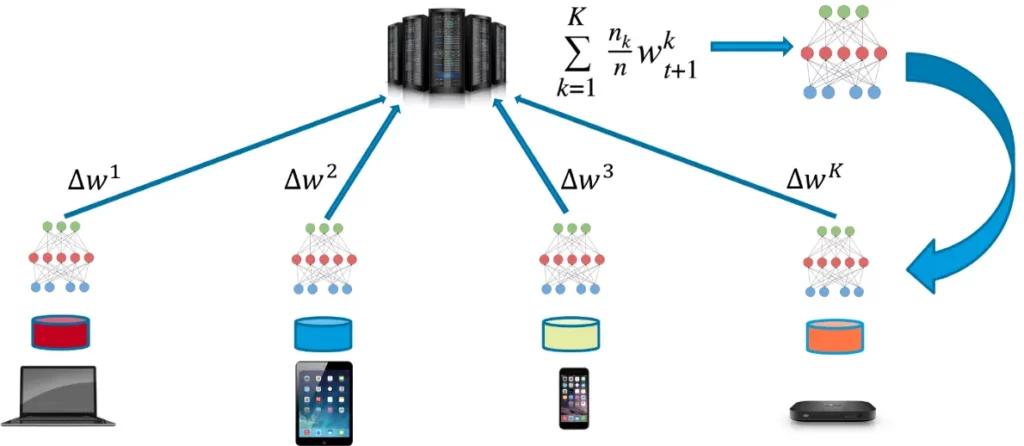
The summary of the steps we take to do this is as follows:
- A generic model (i.e. neural network) is created at a server. The model will not be trained on the server but on the users’ devices (the majority are mobile devices).
- The model is sent to the users’ devices where the training occurs. So the same model (i.e. neural network) is trained parallelly on different devices, according to their private data.
- Just the trained model (i.e. parameters or gradients) is shared back to the server.
- The server averages the trained parameters from all devices to update the generic model based on the federated averaging algorithm.
This way, a model is trained using private data without being moved from the devices. The next figure from a post by Jose Corbacho summarizes the previous steps.
Even though the data isn’t shared with the server, the process is not 100% private, and there’s still a possibility of obtaining information about the data used to train the network and calculate the gradients. The next section discusses how privacy is not entirely preserved using federated learning.
Federated Learning Doesn’t Guarantee Privacy
Federated learning has some privacy advantages as compared to sharing private data with data centers. The benefits also include the ability to build highly-customized machine learning models based on the user data, while avoiding using hits to a user’s bandwidth for transferring the private data to the server.
Undoubtedly, not sharing the data with data centers and keeping it private is an advantage—but there are still some risks. The reason is that there remains a way to extract some private information from the data.
After the generic model is trained at the user’s device, the trained model is sent to the server. Given that the model’s parameters are trained based on the user’s data, there is a chance of getting information about the data from such parameters.
Moreover, joining the user’s data with data from other users has some risks and this is mentioned in the Google research paper:
Here, the seminal paper on federated learning makes it clear that there are still some risks, and data privacy is not 100% guaranteed. Even if the data is anonymized, it’s still vulnerable.
The updates transmitted from the device to the server should be minimal. There’s no need to share more than the minimum amount of info required to update the model at the server. Otherwise, there remains the possibility of private data being exposed and intercepted.
The private data is this vulnerable, even without being sent explicitly to the server because it’s possible to restore it based on the parameters trained by such data. In the worst case when an attacker is able to restore the data, it should be anonymous as much as possible without revealing some user’s private information like the name for example.
It’s possible to reveal the words entered by a user based on the gradients for some simple NLP models. In these case, if the private data already contains some information (i.e. words) about the user, then such words could be restored, and thus the privacy would also not be preserved.
The original paper for federated learning didn’t mention a clear example in which the private data could not be deduced, but it mentioned a case in which it would be difficult (which implies still possible) to extract information about a user’s private data by averaging and summing gradients. The example they include involves revealing information about private data from complex networks like CNNs. Here’s what the paper mentioned:
In essence, there’s no way to 100% prevent an attacker from getting information about the samples used for calculating the gradients of a neural network. But the key is making things harder for the attacker to get such information. It’s like a cavern puzzle, where you should make it difficult as possible to solve.
This is the case for a convolutional neural network (CNN) because it usually has many layers connecting the input to the output, resulting in a large number of interleaving gradients. These gradients render it difficult (though attacks are still possible) to find a relationship between the inputs and the outputs based on the available gradients.

To summarize the previous discussion—even if the private data itself is not shared with the server, the gradients of the trained network are, which makes it possible to extract information about the training samples. The paper discussed 2 main measures you should take to maximize privacy:
- Sharing the minimum of information required to update the generic model at the server.
- Making the neural network as complex as possible so that it’s difficult to use the available gradients (after being averaged and summed) to extract information about the training samples.
The next section summarizes a paper that discusses some specific privacy and security issues related to federated learning.
Privacy and Security Issues of Federated Learning
In a recent paper—Ma, Chuan, et al. “On safeguarding privacy and security in the framework of federated learning.” IEEE Network (2020)—a number of privacy and security issues related to federated learning are discussed.
The paper started by introducing the basic model for federated learning, according to the next figure. This figure shares some similarities to Jose Corbacho’s post.
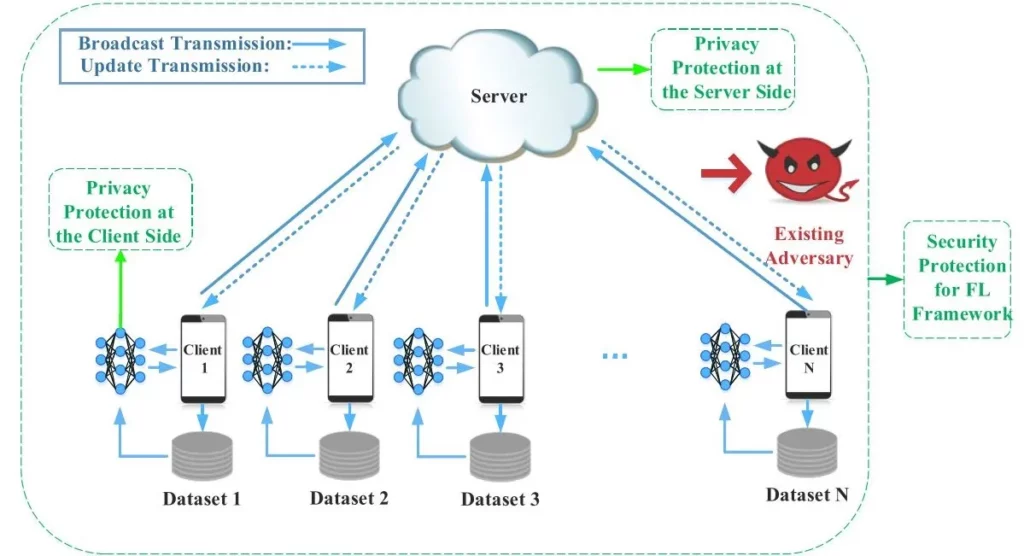
The paper addresses both the security and privacy issues for federated learning. The difference between security and privacy issues is that security issues refer to unauthorized/malicious access, change or denial to data while privacy issues refer to unintentional disclosure of personal information.
The paper classified the protection methods for the privacy and security issues into 3 categories, which are:
- Privacy protection at the client-side
- Privacy protection at the server-side
- Security protection for the FL
Privacy Protection at the Client-Side
Regarding privacy protection at the client-side, the paper discussed 2 ways which are perturbation and dummy:
- Perturbation: Adding noise to the shared parameters to the server so that attackers cannot restore the data or at least not able to get the identity of the user.
- Dummy: Alongside the trained model parameters at the client-side, some dummy parameters are sent to the server.
Privacy Protection at the Server-Side
Privacy protection at the server side is necessary because, as the paper mentioned, when the server broadcasts the aggregated parameters to clients for model synchronizing, this information may leak as there may exist eavesdroppers. The paper mentioned some ways to preserve the privacy at the server side which are aggregation and secure multi-party computation.
- Aggregation: To make revealing information about the user’s data more complex, the parameters from different users are combined together.
- Secure Multi-Party Computation (SMC): The parameters sent from the client to the server should be secured by encrypted it so that an attacker will find it difficult to get information about the user.
Security Protection for the Federated Learning Framework
After the client trains the model by its private data, the model is sent to the server. At this time, an attacker might make some changes to the model to make it behave for their benefit. For example, the attacker might control the labels assigned to images with certain features.
The paper suggests 2 ways to secure the design of a federated learning pipeline: homomorphic encryption and back-door defender.
- Homomorphic Encryption: The model parameters are encrypted so that an attacker finds it difficult to interpret; thus, they’re unable to be changed.
- Back-door Defender: A mechanism(s) for detecting malicious users who try to access the generic model and make updates to it that change its behavior, according to their needs.
The next section provides a quick summary of a paper that is able to reconstruct images by inverting gradients.
Reconstructing Private Data by Inverting Gradients
According to a recent research paper—Geiping, Jonas, et al. “Inverting Gradients — How easy is it to break privacy in federated learning?” arXiv preprint arXiv:2003.14053 (2020)—simply sharing the gradients but not the private data still uncovers private information about the data. Thus, federated learning has not entirely achieved one of its goals, which is keeping user’s data private.
As we mentioned in the previous section, one thing that makes it harder for an attacker to get information about private data is the existence of many gradients, like those available in CNNs. The main proposal of this paper is to reconstruct images based on the gradients of the neural network with high quality. Successfully doing that means the privacy is not guaranteed even if just the parameters, not the data is shared with the server.
The paper proved that the input to a fully connected layer could be reconstructed independently of the network architecture. Even if the gradients are averaged through a number of iterations, this doe not help to protect the user’s privacy.
The paper proves that it is possible to recover much of the information available in the original data. The key findings from this paper are summarized in the following points:
- Reconstruction of input data from gradient information is possible for realistic deep architectures with both trained and untrained parameters.
- With the right attack, there is little “defense-in-depth” — deep networks are as vulnerable as shallow networks.
- We prove that the input to any fully connected layer can be reconstructed analytically independent of the remaining network architecture.
- Especially dishonest-and-curious servers (which may adapt the architecture or parameters maliciously) excel in information retrieval, and dishonesties can be as subtle as permuting some network parameters.
- Federated averaging confers no security benefit compared to federated SGD.
- Reconstruction of multiple, separate input images from their averaged gradient is possible in practice, even for a batch of 100 images.
The next figure, taken from the paper shows, an image, and its reconstruction. The original image is reconstructed with high quality (with little degradation) based on the shared gradients to the server.

Conclusion
This article discussed some of the privacy and security issues in federated learning by summarizing 3 papers. It’s clear that it’s immensely challenging to preserve a user’s privacy, even if only sharing gradients returned by training the global model (e.g. neural network). Even though the data used for training local network updates isn’t shared, it is possible to reconstruct that data.
Comments 0 Responses