
This guide describes how to process audio files in Android, in order to feed them into deep learning models built using TensorFlow.
TensorFlow Lite’s launch and subsequent progress have reduced the distance between mobile development and AI. And over time, don’t be surprised if app stores eventually end up flooded with AI/ML-powered apps.
With mobile, audio can be an integral part of various user experiences, Wouldn’t it be great if we could develop various kinds of AI-powered apps leveraging device microphones and music that we store inside devices?
It’s not as simple as it sounds—at least at the time of writing this article.
Python has a rich array of libraries that helps in doing different kinds of processing with audio data. Those who have performed audio processing in Python can vouch for how powerful the librosa library is.
But the same is not the case with Java. In Java world, there’s a real dearth of audio processing libraries even for basic processing operations, and this acts as a huge blocker to build TensorFlow based Android apps with audio classification capabilities. But with challenge comes opportunity 🙂
The JLibrosa library has been built to solve this problem, providing audio processing capabilities in Java to generate various feature values similar to Python’s Librosa. This library has been made as an open-source library and you can find more details on the library and its features on its GitHub page:
Once processed, the next challenge is about how to feed this processed audio data in Android/Java to TensorFlow Lite models for prediction. Note that TensorFlow Lite models require data to be in the form of a Tensors to run inference.
TensorFlow Java libraries have explicit support for these tensor conversions for images — but for audio data, we’d be required to do some explicit processing before converting Java primitive data to its tensor equivalent.
In this article, we’ll see how to address both these challenges with a sample app in Android. By the end of this article, you’ll have learned:
→ JLibrosa’s capabilities and how to use it to process audio data in an Android environment.
→ We will also see how to generate tensors for various audio processing features with TensorFlow support libraries.
Android — TensorFlow Lite Model Process Diagram:
The diagram below summarizes high-level processing associated with the deployment of TensorFlow Lite models in Android.
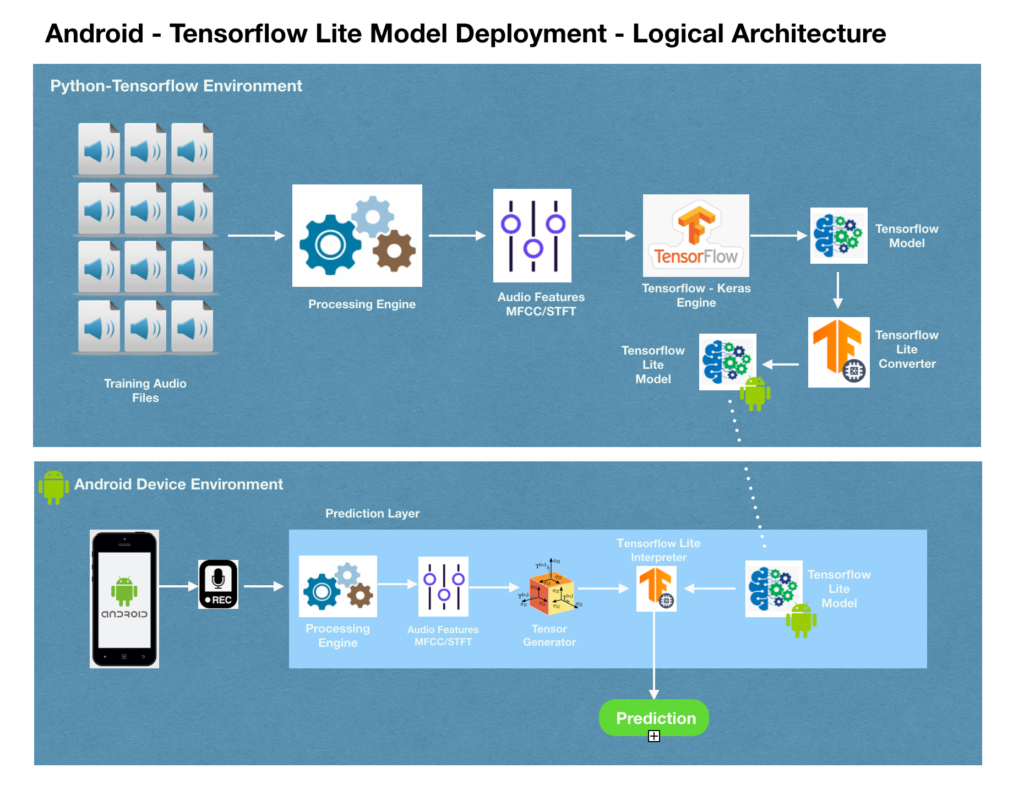
Most readers who are familiar with TensorFlow can easily understand the model generation part of this workflow— where the model is generated from a Python-Anaconda-Tensorflow environment, and the generated model is converted into TensorFlow Lite format.
This article will primarily focus on deploying TFLite models in an Android environment, leveraging JLibrosa for audio processing purposes.
Defining our Project: Music Genre Classification App in Android
Consider this—You’re listening to a song on a drive and you’re curious to know what genre the song belongs to. Wouldn’t it be great if you had a mobile app that lets you record the song and predicts its genre…This is the app we’re going to build in this article. Along the way, we’ll be covering the nitty-gritty step-by-step associated with audio data processing and model deployment.
To build this, we’ll be utilizing an audio classification model built with TensorFlow and that has been converted into TFLite. We’ll then deploy it in a demo Android app built with the core UX in mind. This app will use the device microphone to record audio and then feed the processed data to TFLite model towards predicting it’s genre.
Refer to this video to see the demo of the functioning app.
Audio Processing Primer:
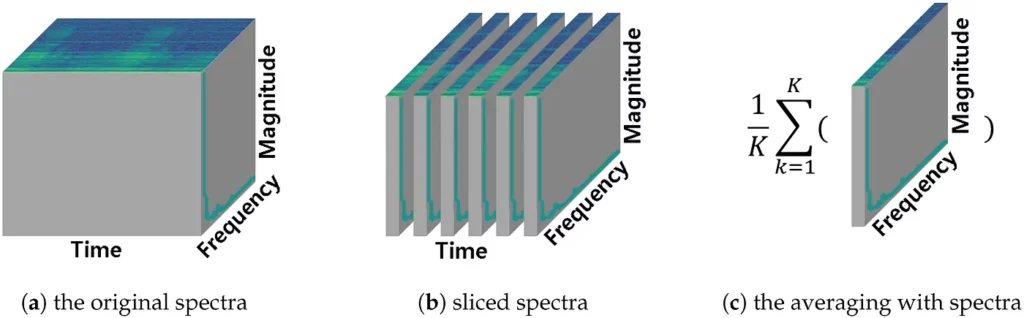
Before getting into the implementation details, we need to step back and understand some of the fundamentals related to audio processing, so we can effectively perform them in an Android environment.
Please note that this article is not designed to explain, in detail, the science behind audio processing and sound waves. We’ll quickly touch upon the basics, which should allow us to move ahead to the implementation in Android (Java) with TensorFlow Lite.
You can refer to the following article if you would like to understand these fundamentals in greater detail:
Audio processing is a complex field and isn’t quite as straightforward as text or image processing. The primary challenge with audio processing is that we cannot usually visualize the data — as is the case with images/text. This makes the data harder to work with, but it also hinders excitement around its possibilities.
But once we understand the basics, it can be a really fascinating area to work on.
Say you’re listening to music via an audio file on your phone. What exactly happens under the hood here? Audio files contain various binary data representing amplitude, frequency, and time information of sound waves, and a given audio player reads that data to play that data as music.
These amplitude, frequency and time in its direct form may not be sufficient to provide key features of audio data. These data attributes could be further processed to derive additional features that would act as key input to build AIML models.
The following are some of the key features we can extract from audio data by processing it:
- MFCC [Mel Frequency Cepstral Coefficients] — This is by far, most commonly used feature for building audio based prediction models. It basically represents overall shape of an audio wave over a small set of features.
- STFT [Short Term Fourier Transform] — STFT is another commonly used feature, which is about splitting your audio data into multiple segments and computing fourier transform for them.
- MelSpectrogram — MelSpectrogram is a spectrogram representation of audio wave, where the frequencies are converted into Mel scale.
- Zero Crossing Rate — The zero–crossing rate is the rate of sign-changes along a signal, i.e., the rate at which the signal changes from positive to zero to negative or from negative to zero to positive.
- Spectral Centroid — It indicates where the ”centre of mass” for a sound is located and is calculated as the weighted mean of the frequencies present in the sound. If the frequencies in music are same throughout then spectral centroid would be around a centre and if there are high frequencies at the end of sound then the centroid would be towards its end.
TFLite Model Training
As mentioned above, we will be developing a music genre classification — Android app, and we’ll use the pre-trained TensorFlow model generated in the following repo for this purpose:
Here the author would have trained TensorFlow model using a Keras CNN in h5 format. We’re going to take this model and export it as a TFLite model using the TFLite Converter.
from tensorflow.keras.models import load_model
import tensorflow as tf
model = load_model('../models/custom_cnn_2d.h5')
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
#Load the TFLite model and allocate tensors
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
#Get input and output tensors
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
#Save the TFLite model
with tf.io.gfile.GFile('model.tflite', 'wb') as f:
f.write(tflite_model)As shown here, we’re loading the model and converting the model into .tflite format. Once converted, we’ll be using the model in an Android environment to build our app.
Recording Sound in Android
We’re now ready to build our Android app that records audio and predicts its genre. I’m not an Android expert and have very limited expertise in it. So we’ll leverage this simple android app and modify it to support our use case.
We will modify the app such that it generates a .wav file of the recording. Once the .wav file is recorded, we will process the audio features and feed them into our TFLite model to predict the song’s genre.
JLibrosa
As stated above, JLibrosa is an open source Java library that has been developed to address the gap in the Java/Android ecosystem with regards to audio processing. JLibrosa, in its current version, supports audio files with ‘.wav’ file extension and helps in the following processing:
→ Load audio files in .wav format and read magnitude values.
→ Generate MFCC values from magnitude values.
→ Generate STFT values from magnitude values.
→ Generate MelSpectrogram values of magnitude values.
It’s a simple Java library you can include in your Android project, using the below steps:
→ Download the latest version of the jLibrosa library from GitHub.
→ Change to ‘Project’ view in Android Studio.
→ Add the library into the ‘libs’ folder of your project.
→ Right click on the library and select ‘Add as Library’ option.
Please refer the the test jLibrosaTest.java file for more specific details.
TensorBuffer and Tensor Processing in Java
Good…so now we’ve read the audio files and generated the feature values as Java arrays. Now our next step is to pass on these Java array values to our TFLite model for prediction.
TFLite is essentially a wrapper over models built using TensorFlow—as such, they work with tensors and not Java arrays. So the Java arrays that we’ve generated with JLibrosa need to be converted into tensors so they can be fed our TFLite model.
TensorFlow Lite has a support library that helps us perform various kinds of tensor processing of Java array values, with explicit methods to support image data.
But for audio processing, this isn’t as explicit. Also, MFCC/STFT features are more complex: they’re multi-dimensional in nature, and the models are trained with CNNs, which require that we generate multi-dimensional tensors in Java.
In-depth usage of the TFLite interpreter and its functionalities are out of the scope of this article, so I’ll jump into the basic details of how to identify the input data shape.
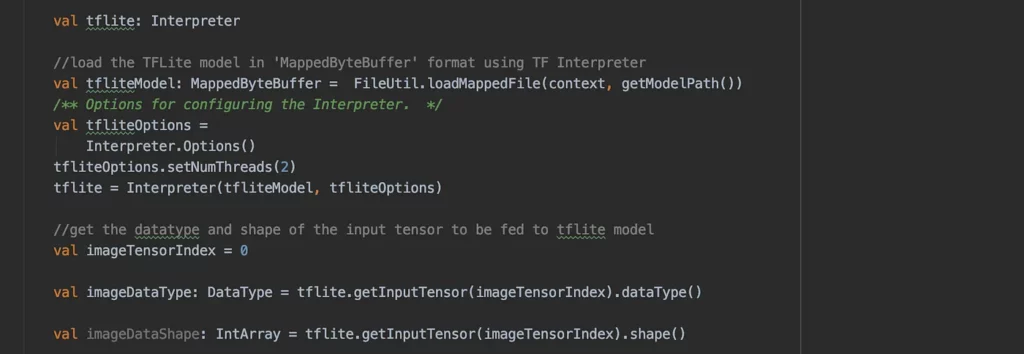
The below code helps us load the model and read the input shape of the tensor to be fed to the model. When you print the imageDataShape and imageDataType values — you’ll find it’s an intArray with shape 1x128x129x1, and its datatype is float. As such, we need to generate the tensor with the above shape and convert it into a ByteBuffer in order to execute the model.
Next, let’s take a look at how we actually generate the tensor.
First, we initiate the ByteBuffer with the required size. Float has a byte size of 4— hence, the ByteBuffer variable is created with the required size.
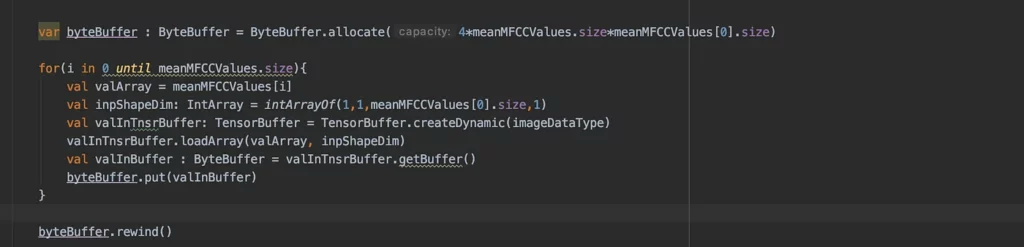
The TFLite support library has a useful feature to create tensors, with its TensorBuffer.createDynamic(
After creating the tensor, we can generate the ByteBuffer from it and have it fed to the model for prediction.
Conclusion
We’ve come to the end of this article. To summarize, we’ve seen how ML-based audio processing is difficult in Android due to a lack of libraries—we also explored how JLibrosa helps in solving the problem.
We have also seen how the processed data from JLibrosa needs to be converted into tensors in order to feed them into a TFLite model for prediction. We have seen all these elements working together in a live example of an Android app designed to classify music genres based on audio recorded from the device.
As mentioned earlier, mobile audio-related use cases are numerous, and in the coming months, we should see some interesting applications evolve in this space.
Audio processing is quite a task to be performed on mobile hardware, and usually the latency associated with the entire process is quite considerable. In this app, we have handled this by running the entire process as a background process.
We could improve the latency of TFLite predictions in Android by leveraging hardware accelerators like GPU (Graphical Processing Unit) delegates and NNAPI (Neural Network API) delegates. I’ll be writing my next article exploring what it takes to use these above delegates and how they help in terms of prediction speed and latency. Stay tuned here for more exciting learning!
Comments 0 Responses